Оптимизация риск-аверсивных гибридных команд человек-ИИ
††спасибо: Данная работа частично поддержана проектом CHIST-ERA-19-XAI010 SAI. Исследования М. Конти и А. Пассарелла частично финансировались в рамках PNRR - M4C2 - Investimento 1.3, Partenariato Esteso PE00000013 — «FAIR» при поддержке Европейской комиссии в рамках программы NextGeneration EU..
Аннотация
Ожидается увеличение случаев совместной работы людей и ИИ-систем в рамках так называемых гибридных команд. Рост сотрудничества прогнозируется по мере повышения компетентности ИИ-систем и расширения их внедрения. Однако их поведение не лишено ошибок, что делает гибридные команды весьма подходящим решением. В связи с этим рассматриваются методы повышения эффективности таких команд, состоящих из людей и ИИ-систем. В контексте гибридных команд и люди, и ИИ-системы будут называться агентами. Для повышения производительности команды по сравнению с индивидуальной работой агентов предлагается менеджер, который обучается по стандартной схеме Reinforcement Learning оптимальному делегированию ответственности за принятие решений любому из агентов с течением времени. Дополнительно направляется обучение менеджера, чтобы минимизировать количество изменений в делегировании, вызванных нежелательным поведением команды. Демонстрируется оптимальность работы менеджера в нескольких grid-средах, включающих состояния сбоя, которые прерывают эпизод и должны быть исключены. Эксперименты проводятся с командами агентов, имеющих разную степень приемлемого риска (в виде близости к состоянию сбоя), и оценивается способность менеджера принимать эффективные решения по делегированию в соответствии с его собственными ограничениями, основанными на риске. Эти решения сравниваются с оптимальными. Результаты показывают, что менеджер успешно обучается желаемому делегированию, приводящему к траекториям команды, близким/в точности оптимальным по длине пути и количеству делегирований..
Ключевые термины:
reinforcement learning; intervention; delegationI Введение
Производительность, достигаемая системами искусственного интеллекта, продолжает расти, и поэтому мы ожидаем увеличения их внедрения для создания сценариев, в которых люди и ИИ-системы, обозначаемые нами как агенты, функционируют в качестве «гибридной команды». В гибридной команде задачи могут быть делегированы одному агенту или выполняться параллельно несколькими человеческими и ИИ-агентами. [1, 2, 3, 4, 5]. Как видно из предыдущих примеров [6, 7, 8, 9, 10, 11], люди и искусственные агенты, безусловно, не свободны от ошибок, поэтому и те, и другие способны принимать ошибочные решения, вызванные ошибками, рискованным поведением и т. д. Для обеспечения успешной работы необходимо учитывать меры по смягчению этих проблем. В некоторых случаях это приводит к проектированию систем, которые воздерживаются от принятия решений при низкой уверенности/опыте. [12, 13]. Следовательно, мы используем менеджера, который контролирует операции гибридной команды и со временем делегирует ответственность принятия решения тому или иному агенту в зависимости от контекста конкретной задачи и ожидаемой производительности агентов в каждый конкретный момент времени. Менеджер обучается на основе наблюдений за контекстом и поведением, чтобы оптимально принимать решения о делегировании..
Мы выделяем четыре ключевые особенности нашего менеджера. Во-первых, очевидно, что менеджер отдает приоритет выбору агентов, которые обеспечивают более высокие шансы на успех, основываясь на собственной оценке производительности отдельных агентов в любой момент времени. Во-вторых, метрика производительности агентов, используемая менеджером, не зависит от тех, что применяются для обучения отдельных агентов на той же задаче. Это гарантирует, что менеджер не делает необоснованных предположений относительно доступа к приватной информации агентов или того, что он ограничен той же метрикой идеального поведения. В-третьих, вмешательства менеджера (т.е. решения о выборе делегирования) также основываются на ограничениях, касающихся поведения и результатов командных решений. Как правило, такие ограничения указывают, насколько гибридная команда близка (или далека) от критических условий, которые могут иметь катастрофические последствия (например, инцидент в сценариях вождения). Эти ограничения вместе с оценками действий агентов определяют точки вмешательства. Следовательно, менеджер может оставаться в фоновом режиме до тех пор, пока не потребуется вмешательство. В-четвертых, менеджер обучается оптимизировать производительность команды путем выбора подходящих делегирований и учится минимизировать число в таких вмешательствах. В реалистичных сценариях менеджеры, которые слишком часто переключаются между командными агентами, могут оказаться непрактичными, действительно.
Мы кодируем эти признаки в стандартную схему Reinforcement Learning, которую полностью описываем в [14]. Конкретно, модель вознаграждения менеджера будет получать обратную связь на основе вознаграждения, включающую штрафы за делегирования, приводящие к нарушению ограничений. Величина штрафов будет указывать, насколько сильно менеджер должен избегать вмешательства, что неявно отражает его неприятие условий, ведущих к необходимости вмешательства. Это будет мотивировать менеджера выявлять агентов, наилучшим образом соответствующих его ограничениям в отношении поведения. Кроме того, вознаграждение менеджера будет различать успех и неудачу задачи, чтобы гарантировать, что менеджер также распознает успешное поведение в отношении основной задачи. В совокупности эти аспекты будут стимулировать политику поведения менеджера, которая отдает приоритет успешному командному поведению и снижению частоты вмешательств менеджера..
Хотя мы рассматривали аналогичные концепции в предыдущих работах, [15, 16, 17], есть отличительные факторы для нашей модели. Во-первых, в [15], мы предлагаем модель обучения с подкреплением (Reinforcement Learning, RL), сочетающую когнитивно инспирированное обучение на основе экземпляров (Instance-Based Learning, IBL) [18] и RL [19] изучить модель делегирования, основанную на понимании поведения, вдохновленного человеческим. На каждом временном шаге менеджер выбирал следующего делегированного агента. Мы расширили сценарий делегирования в [16] к случаям гибридных команд в контексте вождения с ограниченным восприятием агентов. Данный метод аналогично основывался на делегировании управляющего на каждом шаге эпизода. Кроме того, наблюдение управляющего формировалось путем объединения наблюдений агентов команды. Для нашей работы в [17], мы сосредотачиваемся на случаях, когда агенты могут различаться по действиям, которые они способны выполнять в среде. Мы требовали согласованности для состояний, которые агенты могут посещать, но разнообразие действий означало, что агенты могут перемещаться в среде различными способами. Для нашей новой модели [14], В отличие от наших предыдущих работ, данный подход позволяет изолировать модель менеджера от моделей агентов. В отличие от предыдущих случаев, менеджер обладает полностью независимым представлением о состояниях и может наблюдать изменения состояния только в точках вмешательства. Таким образом, менеджер игнорирует промежуточные состояния, устраняя зависимость от согласованности между моделями менеджера и агентов. Кроме того, мы устраняем прежнее требование делегирования менеджером каждого временного шага, что позволяет агентам функционировать в течение интервалов временных шагов. Дополнительно мы изолируем представление менеджера о желательном поведении, устраняя предположения о сходстве между обратной связью менеджера и агентов относительно действий/поведения..
Основной вклад, представленный в статье, заключается в анализе оптимальности нашего менеджера делегирования, описанного в [14], который поддерживает управление гибридными командами разнородных агентов. Переход от [14], мы представляем команды агентов, демонстрирующих разнообразные модели поведения в соответствии с их собственной концепцией избегания риска. Эти агенты используются для создания команд при обучении и тестировании нашей модели менеджера. Мы обучаем нашего менеджера идентифицировать агентов, способных успешно перемещаться в среде, избегая нарушений ограничений, установленных менеджером. В отличие от нашего сценария в [14], мы не рассматриваем случаи, когда несколько агентов перемещаются одновременно в среде; вместо этого мы сосредоточены на демонстрации оптимальности для отдельных команд без дополнительных агентов, что предотвращает переход наших сред в нестационарное состояние. Данный сценарий и ограничение одной командой позволяют сравнить нашу команду с оптимальным решением. По результатам тестов, в большинстве случаев наблюдается результат на уровне или близкий к идеальному для менеджера.
Оставшаяся часть статьи структурирована следующим образом: Раздел I-A перечисляет дополнительные значимые работы, связанные с методами, используемыми в нашей структуре; Раздел II вводит нашу модель менеджера; Раздел III описывает демонстрационный сценарий и связанные детали; Раздел IV определяет наши тестовые сценарии и предоставляет результаты; а Раздел V завершает работу.
I-A Связанные работы
I-A1 Гибридное обучение с подкреплением
Иерархическое обучение с подкреплением (Hierarchical Reinforcement Learning, HRL) представляет собой набор методов и особенностей, вдохновивших наш подход. Методы HRL обычно используют модели, представленные иерархически. Низкоуровневые политики оперируют на более детализированных уровнях действий и переходов состояний. На этих уровнях модели поведения определяют исходы для последовательностей решений, а высокоуровневые политики могут обучаться выбору этих политик. Поведения на низком уровне называются «опциями» (options), которые выполняются до срабатывания условия завершения. [20], Предложенный подход демонстрирует метод обучения «переиспользуемым» опциям, где новые опции добавляются, если очевидно, что они могут обеспечить повышение производительности. Что касается перехода от одной опции к следующей,, [21] демонстрирует подход для оценки совместимости последовательно выбираемых вариантов, что может помочь снизить сложность перехода от одного варианта к следующему. Хотя это актуально, наша модель предполагает заранее изученные поведенческие политики для агентов команды и отсутствие иерархических уровней абстракции, поэтому мы не следуем распространённому подходу HRL, предполагающему обучение политик на различных уровнях..
Как расширение, концепции HRL могут применяться в сценариях с множеством одновременно работающих агентов. [22, 23, 24, 25, 26, 27, 28, 29]. В сценарии с несколькими агентами агенты могут функционировать одновременно, пытаясь выполнить потенциально различные задачи. Как видно из [29], Кооперативные или совместимые задачи могут способствовать обмену знаниями для решения совместимых задач. Использование нескольких агентов также обеспечивает определенную степень совместимости, поэтому как агент, так и задача могут быть учтены для наилучшего соответствия агентов задачам. В рамках нашего предположения о множестве агентов, но единственном действующем агенте, мы не будем проводить прямое сравнение с подходами, основанными на множестве агентов. Для дальнейшего разграничения нашей модели и подходов HRL см. Раздел II.
I-A2 Делегирование
Помимо методов HRL, мы также отмечаем связь нашего подхода с делегированием. [15, 16, 17, 30, 31, 32, 30, 33, 34, 35], где менеджер аналогично обязан подбирать подходящих агентов для задачи с учетом текущего состояния и некоторой меры желательности агента (например, производительность, стоимость и т. д.). Обычно менеджеру поручается принимать решения на основе оценки производительности агентов и соответствующих затрат на выполнение действий. В этой модели менеджеру потребуется более детальное и глубокое понимание желаемого поведения агентов и меры их стоимости. В качестве примера, [32] демонстрирует модель делегирования, использующую показатели производительности или приоритетные значения для обучения модели Reinforcement Learning в условиях алгоритмического триажа. Аналогично, [31] демонстрирует использование затрат, связанных с характеристиками сценария, такими как операции агента или затраты на переключение в вознаграждении менеджера. Эту идею также можно связать с [30] поскольку это демонстрирует случай, когда политика делегирования сохраняет смещение в сторону менее затратной политики, когда это возможно, и переключается на более затратную, но более эффективную политику при необходимости. Поскольку мы сосредоточены на модели менеджера с меньшим количеством предположений относительно доступа к этим признакам, наш подход включает в себя отличные аспекты от выделенных моделей делегирования. Опять же, наш менеджер будет стремиться сократить необходимость принятия таких решений о делегировании, одновременно не требуя доступа к явной мере значений действий для агентов команды..
II Вмешивающийся менеджер
Мы моделируем нашего менеджера с помощью модифицированного Markov Decision Process (MDP) и серии Absorbing Markov Chains (AMC) (см. [14] для получения дополнительных сведений об их общих характеристиках). В частности, пусть быть состоянием в пространстве состояний функции MPD, описывающей поведение менеджера. Определим функцию выявить состояния вмешательства (т.е. состояния, в которых руководитель должен оценить возможное изменение делегирования) как те состояния, где верно. Мы моделируем операции агента, делегированные между двумя последовательными точками вмешательства, как марковскую цепь, где выделяется подмножество состояний которые не требуют вмешательства менеджера (т. е. для которых ), и множество состояний где осуществляются вмешательства.
Между двумя последовательными делегированиями мы моделируем это как поглощающую цепь Маркова (см. [14]) где и являются переходными и поглощающими состояниями соответственно. Когда менеджер принимает решение о следующем делегировании, начинается «новый» марковский процесс, чьи поглощающие состояния — это те, которые инициируют следующее действие делегирования менеджером. Таким образом, MDP менеджера наблюдает только поглощающие состояния базовых AMC, поскольку именно в них менеджер принимает решения, и, как будет объяснено далее, вознаграждения назначаются на основе стандартного подхода Reinforcement Learning. Наконец, далее мы определяем эпизод как последовательность действий от начала задачи до её завершения, что может привести либо к успеху гибридной команды («цель найдена»), либо к неудаче («цель не найдена»).”).
Более формально, для моделирования динамики нашего менеджера мы используем модифицированный MDP, который называем Intervening MDP (IMDP) с
-
•
, пространство состояний MDP
-
•
, множество интервенционных состояний
-
•
, множество ненаблюдаемых делегированных состояний операций
-
•
, пространство действий выбора агента-менеджера
-
•
, функция вознаграждения менеджера
-
•
, функция перехода менеджера
-
•
, набор агентов, доступных для делегирования
-
•
, функция сигнала вмешательства
Более того, функция вознаграждения менеджера определяется следующим образом (предполагается, что она вычисляется в конце эпизода):
| (1) |
где это «частота сигналов», то есть количество раз, когда вмешательства были активированы в течение наблюдаемого эпизода, и является коэффициентом масштабирования, используемым для регулирования степени влияния штрафов на снижение ценности эпизода. Отметим, что при использовании позволяет ограничить масштаб штрафа при обучении с подкреплением (RL).
Менеджер IMDP будет осуществлять переходы из к на основе политики делегированного агента для и . Следовательно, при бесконечном горизонте планирования переходы между состояниями менеджера могут быть описаны
| (2) |
с ссылаясь на вероятности переходов базовой AMC между двумя вмешательствами в рамках конкретной политики агента, делегированного в течение этого временного окна. Использование серии AMCs подразумевает необходимость разрешения промежуточного перехода из состояния вмешательства к началу нового окна делегирования. Это будет происходить неявно в том же состоянии, поэтому мы расширяем определение для учёта этого аспекта. Расширение позволяет представлению переходить из поглощающего состояния, не завершающего эпизод, в рекуррентное состояние, которое инициирует новую цепь AMC. В этом случае модель становится
| (3) |
где является индикатором, обозначающим, было ли выполнено новое делегирование в состоянии . С этим , делегация преобразует текущее состояние в начальное состояние нового AMC, которое продолжается до достижения целевого/терминального состояния или нового поглощающего состояния..
Последний аспект модели менеджера, в соответствии со стандартной схемой RL, — это определение его функции ценности. В частности, политика делегирования менеджера дает функцию ценности для состояния
| (4) |
где позволяет функции ценности менеджера зависеть от переходов AMC в соответствии с делегированием агенту . Оценка значения основана на политике делегирования менеджера и состояния, наблюдаемые в соответствии с делегированными политиками поведения агентов . Модель может быть определена рекурсивно для оценки ожидаемого значения состояния относительно вероятности принятия решения о делегировании. , вероятность следующего наблюдаемого состояния следующая политика делегированного агента , и дисконтированная стоимость следующего состояния . скидка указывает вес для оценочного значения будущих состояний. Менеджер оценивает значения состояний в соответствии со своей политикой поведения через (4), который оценивает ожидаемые вознаграждения для траекторий, ведущих из текущего состояния . Эти вознаграждения, мгновенные или эпизодические, определяются функцией вознаграждения менеджера. и указать значение/вознаграждение для каждого решения, принятого менеджером. Для мгновенных вознаграждений, назначаемых при каждом вмешательстве, менеджер будет наблюдать в (4) немедленная обратная связь, возникающая при переходе в состояние . Для эпизодического случая (т. е. когда вознаграждения присваиваются только в конце эпизода) менеджер наблюдает отложенное вознаграждение, основанное на всех делегированиях, произошедших в течение эпизода. Это достигается путем обратного отслеживания наблюдаемых вознаграждений и присвоения этих значений исследованным состояниям. Оба типа обратной связи согласуются со стандартными методами RL..
Следовательно, мы можем вывести оптимальную функцию ценности как
| (5) |
и функция ценности состояния-действия
| (6) |
Как показано в [14], наша модель соответствует стандартным требованиям RL для сходимости. Кроме того, мы можем использовать методы RL для обучения оптимальной политики менеджера. .
III Конкретный сценарий для анализа оптимальности
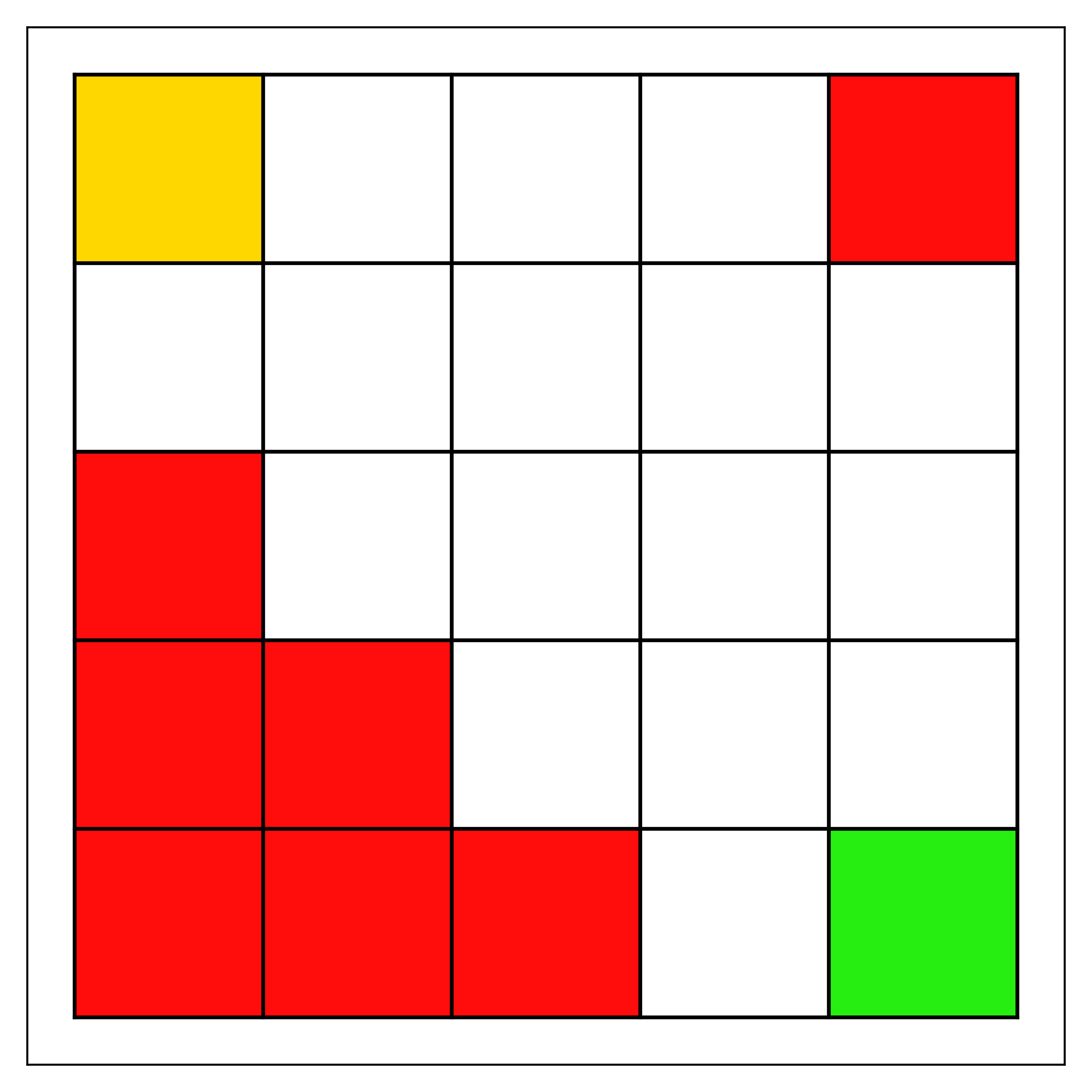
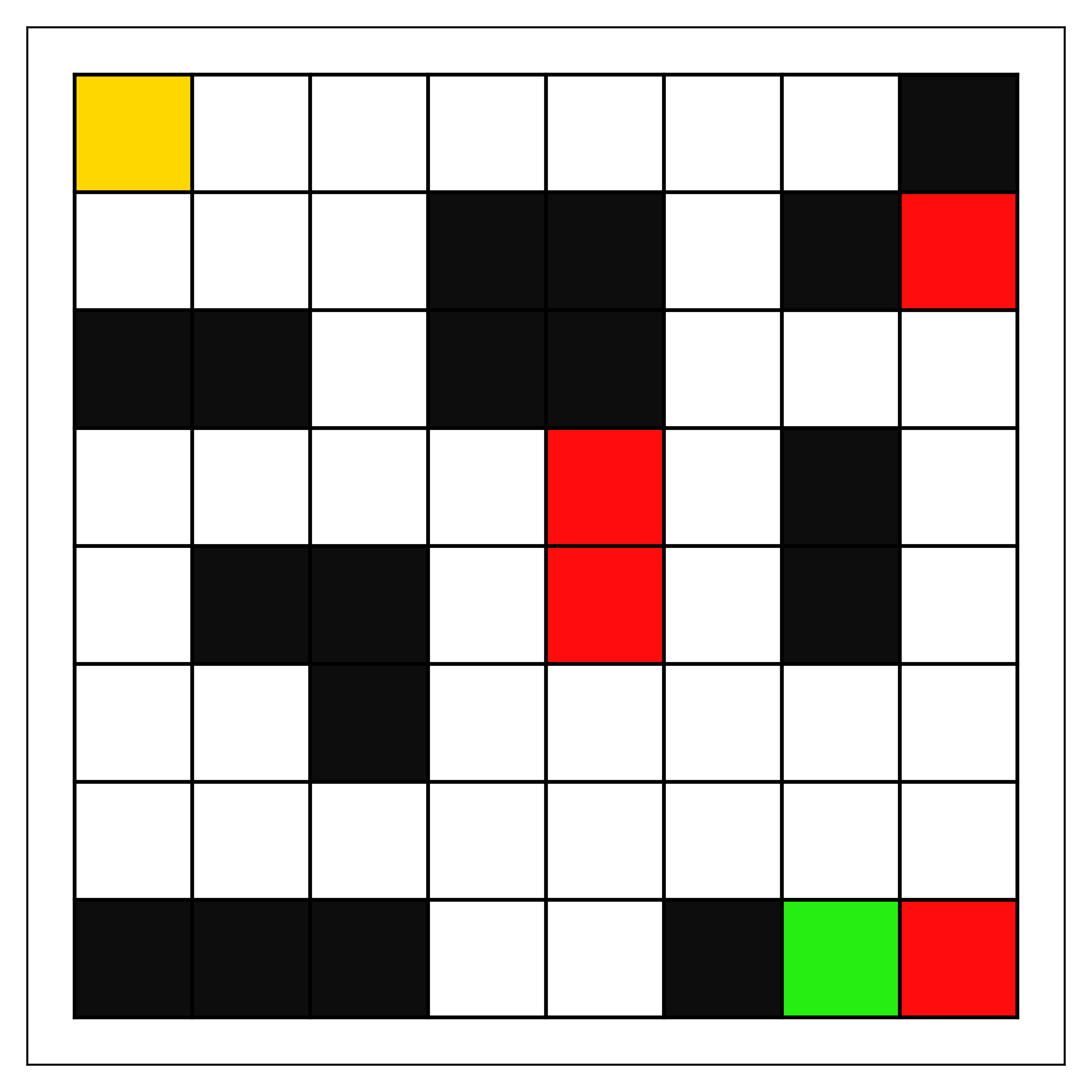
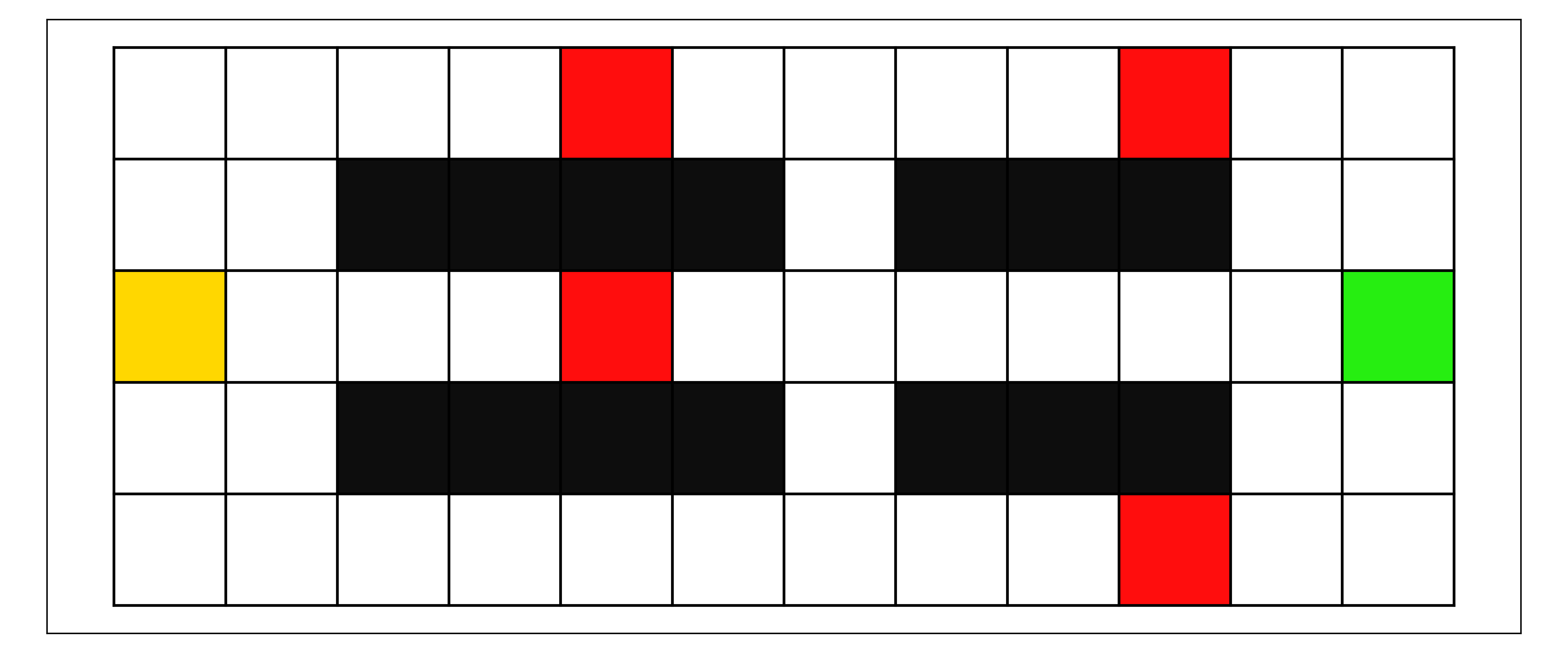
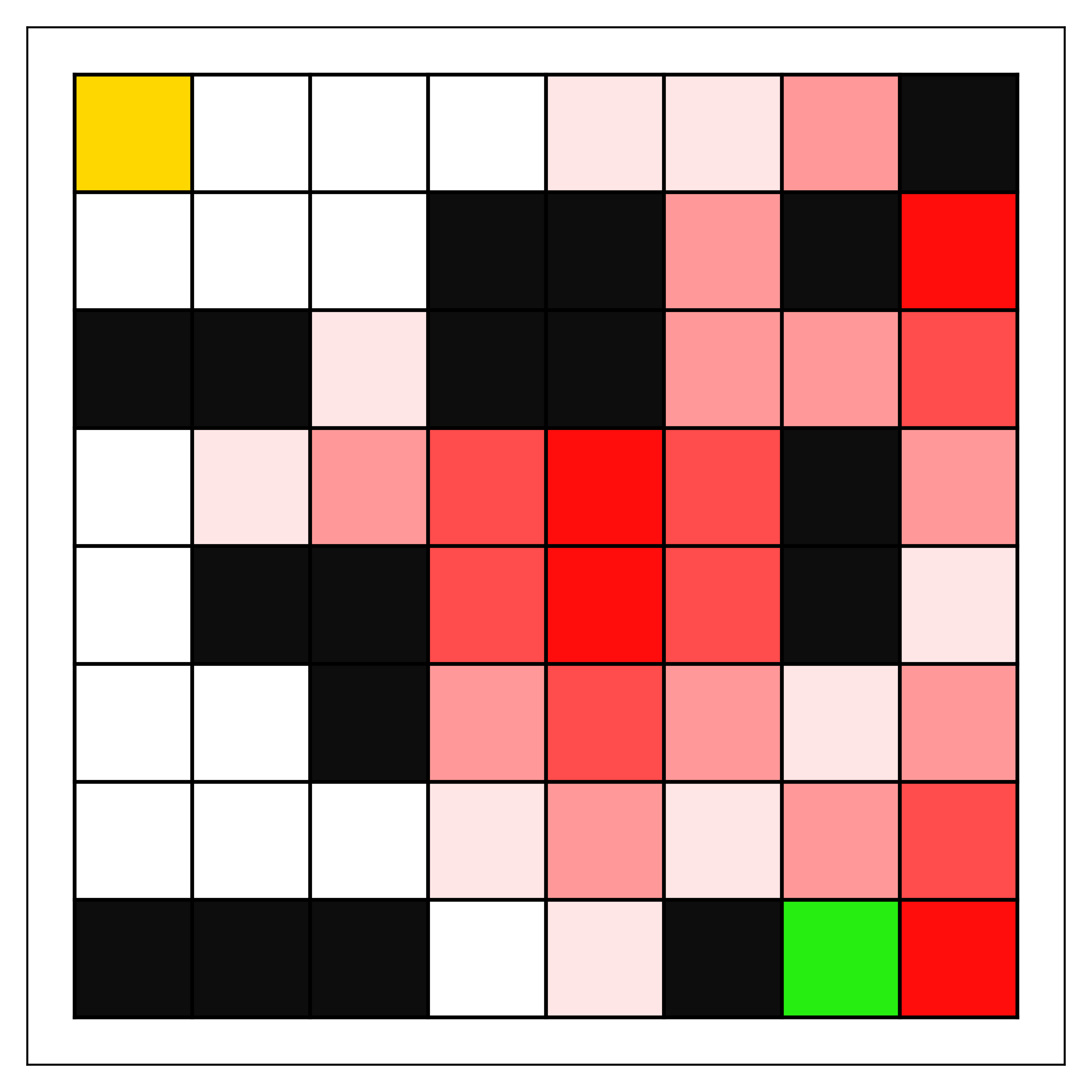
Мы рассматриваем конкретный сценарий, описанный ниже, который особенно подходит для анализа производительности менеджера, определенного, как объяснено в Разделе II относительно идеального оптимального поведения. В частности, мы используем команды агентов, задача которых — навигация в сеточной среде (см. рис.. 1) перемещаясь из начального состояния в целевое. Сеточные среды определяются набором ячеек сетки, по которым агенты перемещаются, выбирая действия, обозначающие направление движения (например, влево/вправо/вверх/вниз). Действия перемещают агентов в соседнюю ячейку в выбранном направлении. Если агент пытается переместиться в направлении стены или границы, в силу природы сеточной среды граница блокирует движение в этом направлении, и агент остаётся в том же состоянии. Мы расширяем сеточную среду, добавляя тип состояния, который обозначаем как «состояние неудачи». Если агент попадает либо в целевое состояние, либо в состояние неудачи, эпизод завершается..
Состояния отказа служат средством для направления поведения менеджера и определения его ограничений. В случае управления агентами, перемещающимися в сеточной среде, наш менеджер будет иметь ограничения, определяющие минимально допустимую близость к состоянию отказа. Если команда нарушает ограничение по близости, то менеджер функция укажет на необходимость вмешательства, и будет принято решение о делегировании. Учитывая характеристики сеточной среды, расстояние будет определяться в соответствии с метрикой Manhattan Distance
| (7) |
для клеток и указывая столбец и строку ячейки соответственно. Мы используем расстояние Манхэттена, так как оно непосредственно соответствует количеству шагов, необходимых для достижения состояния отказа при отсутствии границ. Таким образом, получаем оценку важности близлежащего состояния отказа..
Использование дистанционных понятий оптимальности и безопасности позволит нам непосредственно наблюдать влияние контроля со стороны менеджера на поведение команды. Мы ожидаем увидеть случаи, когда менеджер обучается выбору делегирования, который балансирует риск команды с учетом ограничений менеджера и метрики производительности, используемой агентами для обучения. Конечно, менеджер не будет наблюдать эти метрики производительности, но сможет увидеть, как обученное поведение агентов изменилось в процессе обучения в соответствии с этими метриками. В совокупности это позволяет нам измерить данные факторы, чтобы оценить, насколько эффективно команда и менеджер могут взаимодействовать для выполнения задачи. Мы обсудим эти аспекты и способы их измерения в Разделе III-B.
III-A Навигация в обучении агентов
Для формирования команд агентов мы обучаем агентов навигации независимо, чтобы сгенерировать поведенческие политики для каждого агента. После обучения каждая поведенческая политика определяет кандидата в агенты для команды. Для обучения мы представляем сеточное окружение как MDP. Переходы работают, как описано выше, для поддержки перемещения между соседними состояниями, а агенты получают вознаграждения, отражающие ценность их действий. В независимо обученных моделях агентов мы используем вознаграждения для мотивации желаемого поведения. В задаче навигации мы разделяем вознаграждение на две компоненты для получения наблюдаемого вознаграждения.
| (8) |
где текущее состояние и является ли следующее состояние результатом выполнения действия в состоянии . Сначала агенты получают штраф каждый раз, когда находятся на специфичном для агента расстоянии от состояния сбоя. . Масштаб штрафа зависит от расстояния агента и устанавливается для каждого агента, задаваемый согласно
| (9) |
для from Equation 7. По мере создания уникальных агентов каждый агент будет иметь собственный набор значений для задаётся в качестве параметра для обучения агента. Например, с ближайшим состоянием сбоя , агент может наблюдать
| (10) |
присваивать уникальные штрафные коэффициенты и без штрафа за . Кроме того, как только агент переместился в ячейку, такую что , не будет наблюдаться штрафа за близость.
Помимо штрафа, основанного на расстоянии, мы предоставляем вознаграждения, соответствующие общей задаче навигации. Эти вознаграждения стимулируют выбор кратчайших путей и устраняют ошибочное поведение (например, столкновение со стеной/границей). Данные вознаграждения назначаются в соответствии с
| (11) |
мотивировать агентов к изучению эффективных путей достижения цели.
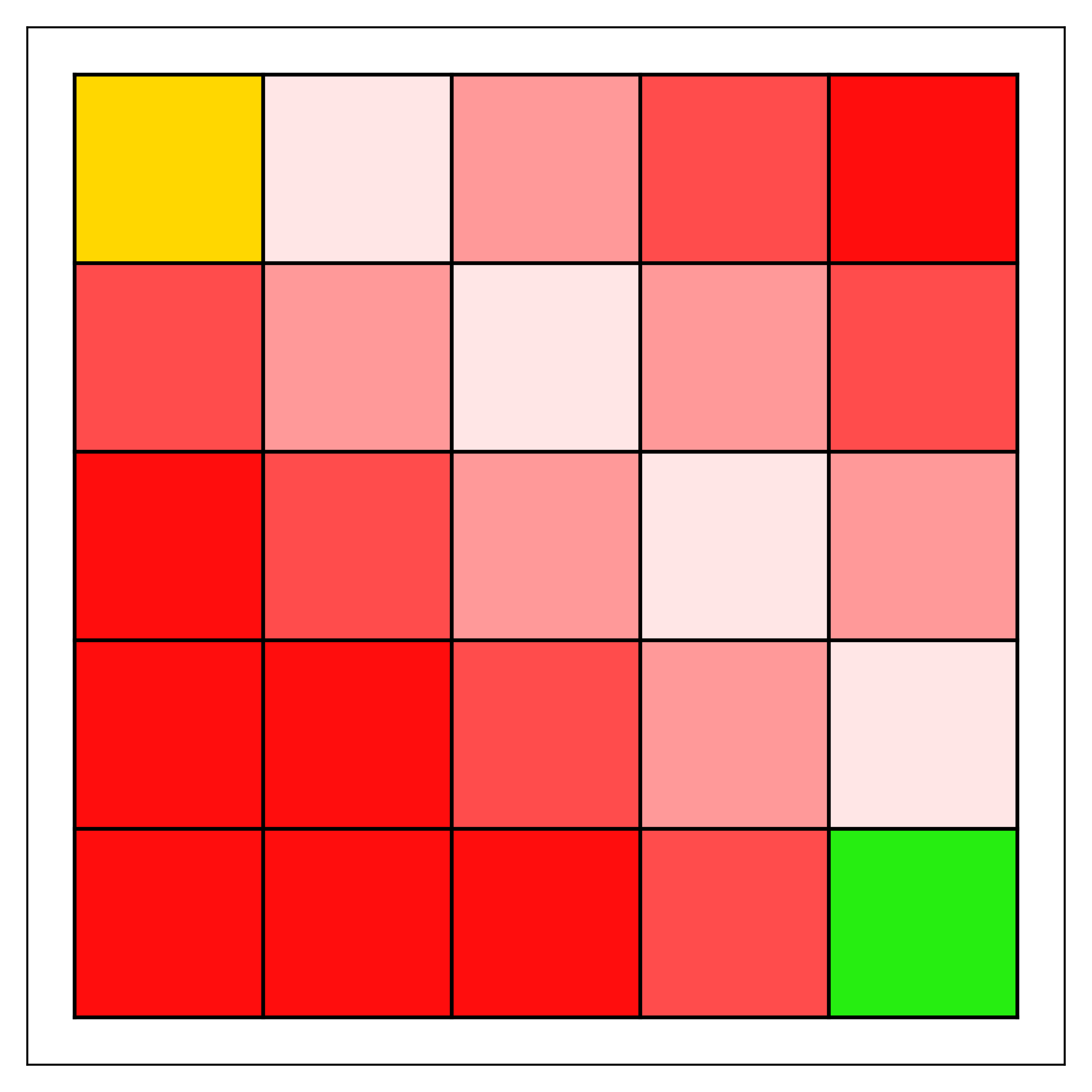
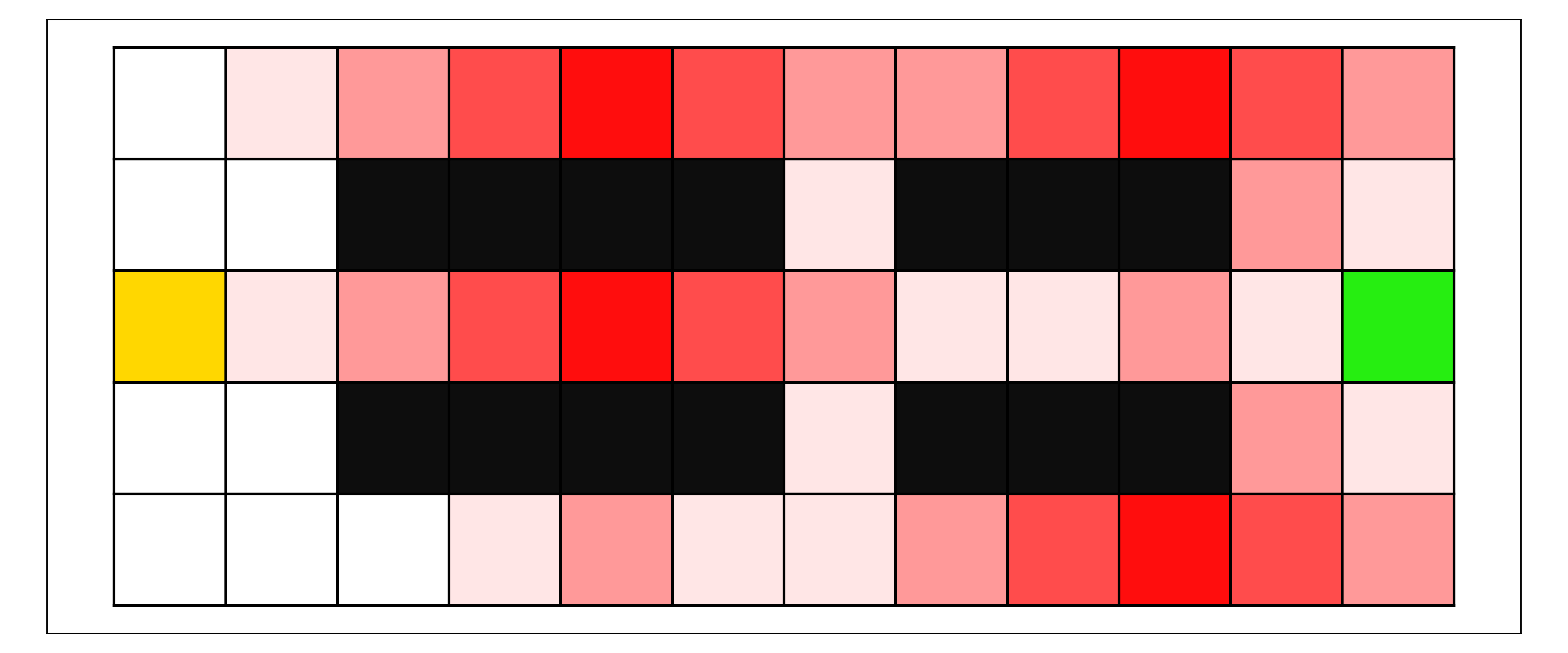
Штраф на основе расстояния определяет вероятность перехода агента в состояние сбоя в процессе обучения эффективному пути. В качестве примера см. рис.. 2, где мы демонстрируем значимость, придаваемую клеткам вблизи состояний отказа, когда безопасное расстояние равно трем. На рисунке наблюдается четкая тенденция снижения важности клеток по мере увеличения расстояния до состояния отказа. Таким образом, исходя из серьезности этих штрафов, путь агента будет отдавать приоритет клеткам, которые вызывают наименьшее беспокойство с точки зрения безопасного расстояния (например, клеткам, расположенным дальше всего слева на рис.. 2(b)). Важно отметить, что это не предполагает какой-либо совместимости или сходства с ограничениями менеджера. Это позволяет создавать ансамбли агентов, где каждый действует в соответствии со своей ранее обученной моделью и соответствующим уровнем приемлемого риска..
III-B Менеджер задач
В соответствии с нашей концепцией, агенты под управлением менеджера будут действовать, выбирая действия до тех пор, пока не возникнет необходимость вмешательства. В случае навигации по сетке, с точки зрения менеджера, это будет означать, что команды совершают ошибки, перемещаясь в состояние, слишком близкое к состоянию сбоя (или попадая в состояние сбоя), согласно ограничениям, определенным менеджером. относительно безопасного расстояния.
Аналогично уравнению 10, менеджер будет использовать функция на основе для текущего состояния . В нашем сценарии расстояние используется для определения такой, что
| (12) |
где устанавливает ограничение менеджера на близость. Таким образом, мы видим, что менеджер не будет вмешиваться, пока минимальное расстояние Манхэттена не достигнет его порогового значения. Это гарантирует, что менеджер основывает решение о вмешательстве на отдельной и совместимой мере безопасности..
Согласно уравнению 1, менеджер наблюдает вознаграждение, которое указывает на успех или неудачу задачи, при этом величина вознаграждения определяется количеством вмешательств. Как определено, значения вознаграждения не зависят напрямую от безопасного расстояния ; вместо этого вознаграждение менеджера будет зависеть от частоты вмешательств. Таким образом, существует неявная зависимость от , но ключевым фактором является поведение делегированных агентов и успех команды в выполнении задачи.
При изолированном рассмотрении взглядов менеджера и агента на безопасность динамика команды будет варьироваться соответствующим образом. Агенты, выбранные менеджером, будут действовать в соответствии с их собственной приемлемой дистанцией безопасности, которая направляет их действия и формируемые траектории. Аналогично, ограничения менеджера на безопасное поведение определяют, насколько агент подходит для делегирования. Команды, полностью состоящие из агентов, принимающих большие риски, чем менеджер, обычно приводят к частым вмешательствам с его стороны, тогда как агенты с более строгой склонностью к избеганию риска потребуют минимального или нулевого вмешательства. Следовательно, эффективность менеджера зависит от доступных агентов, выбора стратегий их работы и способности менеджера коррелировать эти факторы для усвоения желаемого поведения..
Исходя из нашего представления о влиянии менеджера на производительность команды, оптимальное поведение менеджера в данном сценарии будет определяться как сумма длины пути и количества вмешательств менеджера. Акцент на длине пути отражает тип маршрута, который выбирает команда в соответствии с уровнем её неприятия риска, тогда как акцент на вмешательствах явно указывает на степень соответствия команды ограничениям менеджера. Таким образом, эффективность менеджера будет измеряться как
| (13) |
для длины пути и
| (14) |
обозначая количество вмешательств для траектории эпизода . значения для каждого тестового эпизода затем усредняются для расчета средней производительности для управляемой команды. Тесты проводятся путем запуска 50 эпизодов на каждую команду из двух агентов в каждом окружении и случае интервенционного расстояния..
Для определения границ производительности мы измеряем оптимальную стоимость в среде с учетом того, как значения и связаны. Эти значения определяются конкретной средой сетки и ограничениями менеджера. Мы используем алгоритм кратчайшего пути для вычисления минимально возможного значения для для заданного менеджера. Мера кратчайшего пути модифицируется, чтобы учесть ограничения менеджера. Любой путь, который потребует вмешательства, будет иметь увеличенный вес на единицу при каждом таком случае. для обозначения штрафа за вмешательство. Таким образом, алгоритм поиска кратчайшего пути вернет путь с минимальной суммой пройденных ячеек сетки и произошедших вмешательств менеджера.
В случаях, когда показатель эффективности менеджера отклоняется от оптимального, это может быть следствием трех исходов. Во-первых, в команде могут быть только агенты с уровнем избегания выше, чем у менеджера, поэтому их пути длиннее кратчайших возможных. Например, рассмотрим агента, избегающего центрального состояния отказа на Рисунке 2(b). Путь, избегающий этого состояния, потребует дополнительных шагов, которые удаляют от цели и направлены к левой границе, прежде чем развернуться обратно к цели. Более короткий путь возможен рядом с состоянием сбоя, поэтому команда, избегающая этого пути, может получить субоптимальный результат. Во-вторых, менеджер может выбрать агента, который не получил достаточного опыта в части сетки из-за того, что его обучение не включало активного исследования этой области. Если у менеджера есть команда агентов, которая попадает в такую область, может возникнуть небольшая путаница, приводящая к более длинным путям, пока команда не вернется к желаемому маршруту. Наконец, менеджер может просто выбрать субоптимального агента в определенном состоянии, что приведет к менее желательным путям по сравнению с выбором другого агента..
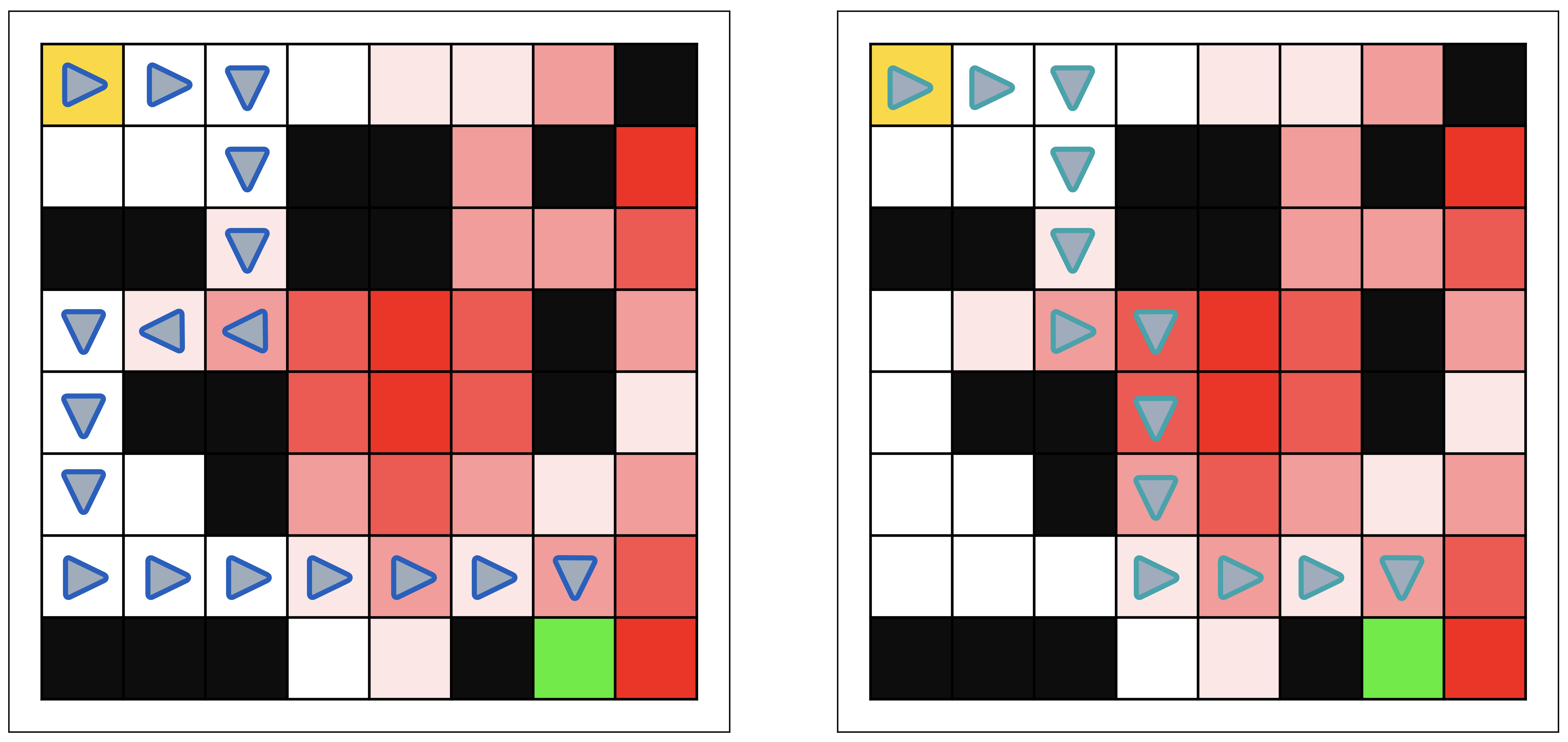
Для конкретных примеров, учитывая нашу метрику эффективности менеджера, мы сравним значения к мере оптимальных путей. Как показано на Рисунке 3, уровни неприятия риска агента определяют путь, который агент использует для перемещения по сеточному окружению. Слева мы видим агента с высокими штрафами за (напр.., и ), в то время как правая сторона демонстрирует поведение при меньших значениях (например., и ). Как показано, сила штрафов за избегание может существенно влиять на длину пути для агента/команды. При совместной работе с менеджером уровни избегания агента и менеджера будут влиять на итоговые пути. Агенты с высокими штрафами, такие как на левой стороне рисунка 3, будет меньше случаев, когда их траектория окажется достаточно близка к состоянию сбоя, чтобы спровоцировать вмешательство менеджера. Следовательно, наилучший менеджер с может достичь при наличии команды таких агентов будет ограничено длиной их пути (т.е.., ). С другой стороны, менеджер с командой агентов, выбирающих пути, такие как правая часть рисунка 3, будет иметь более высокую зависимость от . С , команда инициирует вмешательство и таким образом и , присвоение наивысшего возможного балла . Следовательно, оценка менеджера зависит как от его способности выбирать подходящих агентов, так и от наилучшего возможного поведения, которого может достичь любой агент. Таким образом, наш показатель оптимальности отражает, насколько хорошо менеджер способен достичь этих значений и как команда влияет на его оценку..
IV Результаты
Мы обучаем и тестируем наших менеджеров в нескольких сеточных средах и при различных уровнях неприятия риска. Сеточные среды (см. рис.. 1) предназначены для включения различных уровней сложности навигации и простоты избегания состояния отказа. Кроме того, мы создаем несколько навигационных агентов с различными уровнями избегания риска (см. Раздел III-A) для формирования разнообразных команд для менеджера. Учитывая параметры агента и обучение, все агенты команды обучаются избегать перехода в состояние отказа, но различаются по своей реакции на риск (т.е.., ).
Как отмечено, производительность менеджера сравнивается с оценкой оптимально возможного пути в соответствии с сеткой и соответствующим порогом ошибки, основанным на дистанции для менеджера. Навигационные агенты по определению мотивированы находить пути, минимизирующие штрафы за длину пути и близость к состоянию сбоя, поэтому путь команды будет служить индикатором эффективности менеджера. Учитывая, что каждый агент стремится достичь цели кратчайшим путем, не нарушающим его собственное восприятие риска, выбор менеджером конкретного агента определит длину пути, найденного командой. Следовательно, решения менеджера о делегировании напрямую влияют на краткость пути, выбираемого командой. Если менеджер выбирает агента с более высоким уровнем избегания риска, чем у него самого, команда может сделать больше шагов для достижения цели по сравнению с выбором агента с меньшим избеганием. Таким образом, эффективность менеджера может оцениваться по его влиянию на пути команды и частоту вмешательств..
В таблицах III-III, мы демонстрируем эффективность менеджера в различных средах сетки. Обучение менеджера проводилось в командах с различными уровнями неприятия риска и дистанциями вмешательства менеджера. . Включение вмешательства с нулевым расстоянием служит базовым уровнем для оценки эффективности команды при отсутствии вмешательства без достижения терминального состояния ошибки. Отметим, что обученные навигационные агенты демонстрируют 100% успешность достижения целевого состояния во время тестирования. Это означает, что менеджеру необходимо учитывать только производительность агентов и относительно функции стоимости, определенной в уравнении 13. Агенты, избегающие состояний отказа, обеспечивают согласованность сравнения результатов между различными командами и исключают неоднозначность, вызванную появлением более коротких путей из-за путей с отказами..
| Типы команд | Дистанция вмешательства | |||
|---|---|---|---|---|
| 0 | 1 | 2 | 3 | |
| Нет, Низкий | 8.0 (8.0) | 9.55 (8.0) | 13.14 (12.0) | 15.0 (15.0) |
| Нет, Средний | 8.0 (8.0) | 9.50 (8.0) | 13.31 (12.0) | 15.0 (15.0) |
| Нет, Высокий | 8.0 (8.0) | 9.54 (8.0) | 13.39 (12.0) | 15.0 (15.0) |
| Низкий, Средний | 8.0 (8.0) | 8.0 (8.0) | 12.0 (12.0) | 15.0 (15.0) |
| Низкий, Высокий | 8.0 (8.0) | 8.0 (8.0) | 12.0 (12.0) | 15.0 (15.0) |
| Средний, Высокий | 8.0 (8.0) | 8.0 (8.0) | 12.0 (12.0) | 15.0 (15.0) |
| Типы команд | Дистанция вмешательства | |||
|---|---|---|---|---|
| 0 | 1 | 2 | 3 | |
| Нет, Низкий | 14.9 (14.0) | 15.5 (15.0) | 18.5 (18.0) | 21.0 (21.0) |
| None, Medium | 15.2 (14.0) | 15.5 (15.0) | 18.5 (18.0) | 21.0 (21.0) |
| Нет, Высокий | 15.0 (14.0) | 15.4 (15.0) | 18.9 (18.0) | 21.8 (21.0) |
| Низкий, Средний | 17.0 (14.0) | 17.0 (15.0) | 19.0 (18.0) | 23.0 (21.0) |
| Низкий, Высокий | 17.0 (14.0) | 17.0 (15.0) | 19.0 (18.0) | 23.0 (21.0) |
| Средний, Высокий | 17.0 (14.0) | 17.0 (15.0) | 19.0 (18.0) | 23.0 (21.0) |
| Типы команд | Дистанция вмешательства | |||
|---|---|---|---|---|
| 0 | 1 | 2 | 3 | |
| Нет, Низкий | 15.0 (15.0) | 15.0 (15.0) | 18.0 (18.0) | 24.5 (24.0) |
| Нет, Средний | 15.0 (15.0) | 15.0 (15.0) | 18.0 (18.0) | 24.5 (24.0) |
| Нет, Высокий | 15.0 (15.0) | 15.0 (15.0) | 18.0 (18.0) | 24.5 (24.0) |
| Низкий, Средний | 15.0 (15.0) | 15.0 (15.0) | 18.0 (18.0) | 24.5 (24.0) |
| Низкий, Высокий | 15.0 (15.0) | 15.0 (15.0) | 18.0 (18.0) | 24.5 (24.0) |
| Средний, Высокий | 15.0 (15.0) | 15.0 (15.0) | 18.0 (18.0) | 24.5 (24.0) |
Мы представляем результаты в таблицах в следующем формате. Во-первых, «Team Types» указывает уровень избегания для агента команды относительно приближения к состоянию отказа: None, Low, Medium и High. Эти уровни избегания соответствуют максимальному такой, что , с , , , . Помните, что траектории агентов будут варьироваться в зависимости от этих уровней избегания (см. рис.. 2). В оставшихся столбцах представлены результаты работы команды под руководством менеджеров с различной дистанцией вмешательства. Оценки команды/менеджера указаны как балл команды с последующим расчетным оптимальным баллом в скобках. Оценка рассчитывается на основе комбинации кратчайшего пути и стоимости вмешательства. определено в Разделе III-B.
В Таблице III, мы видим результаты для среды Angle Cliff. В этой сетке у команды будет мало возможностей избежать случаев вмешательства, когда увеличивается. Тем не менее, существует путь по диагонали, по которому агенты могут перемещаться, чтобы минимизировать эти вмешательства (см. рис.. 2(a)). Как показали результаты, менеджер может определить последовательность агентов, генерирующую результаты, близкие к этим оптимальным траекториям. Поскольку агенты обучались находить путь, соответствующий их представлению о приемлемом риске, без предписанного обучения из любого начального состояния, мы можем отнести некоторые субоптимальные траектории (например, команда "None, High" с Intervention Distance: 2) либо к избеганию риска, либо к незначительной путанице агентов при попадании команды в реже встречающиеся состояния. Другими словами, некоторые изменения делегирования и субоптимальное поведение агентов команды могут привести к траектории, слегка отклоняющейся от политически-агностического кратчайшего пути. Это может вызвать возврат (например, действие "right", за которым следует действие "left") для возврата к оптимальной траектории, что увеличивает на один или более. Кроме того, любое единичное отклонение от диагонали приведет к тому, что последующие состояния будут получать дополнительные штрафы, поэтому небольшие отклонения от центрального пути приведут к незначительным изменениям в командном результате. С другой стороны, для команд, где агенты имеют схожий уровень неприятия риска с менеджером (например, "Low, Medium" и ), мы наблюдаем признаки хорошей согласованности между руководителем и командой. в этих случаях показатели хорошо соответствуют нашей мере оптимальности, так как траектории команды согласуются с ограничениями руководителя и приводят к оптимальным результатам.
Для последующих результатов, Таблица III указывает на производительность команды в лабиринте. Как отмечено в разделе III-B, данная среда демонстрирует примеры случаев, когда неприятие риска агентом может существенно влиять на выбираемые пути. Несмотря на возросшую сложность доступных маршрутов, команды показывают высокую производительность и часто приближаются к оптимальному уровню. Как и в предыдущем случае, следует отметить, что отклонения порядка двух менее значительны, чем кажется. В данных условиях это эквивалентно одному шагу в сторону от оптимального пути с последующим возвращением. Кроме того, отклонения от «оптимального» пути объясняются случаями, когда агенты демонстрируют неприятие состояний отказа, выбирая маршруты, отличающиеся от кратчайших. Это наиболее заметно у агентов с высоким уровнем избегания риска. Хотя менеджер менее склонен избегать риска, агент всё равно будет выбирать пути, сохраняющие большее расстояние от состояний отказа, что приводит к отклонению от кратчайшего маршрута, если риск не учитывается. Таким образом, эти команды будут демонстрировать более для оценки эффективности менеджера. Как и в предыдущей среде, мы наблюдаем случаи с сильным совпадением неприятия риска менеджера и агента (например, «None, Low» и ), при соответствующей высокой производительности команды на уровне, близком к оптимальному. С другой стороны, сильное избегание некоторыми агентами (например, "Medium, High" и ) приводит к более длинным путям и более высоким оценкам, чем было бы возможно с агентами, более склонными выбирать короткий путь вблизи центрального состояния отказа. В таком случае менеджер не может заставить команду выбрать короткий путь, поэтому итоговая оценка оказывается выше минимальной/оптимальной. Опять же, менеджер достиг бы этого оптимального значения только в том случае, если бы команда смогла выбрать более «рискованный» маршрут к цели.
В качестве последнего примера мы используем карту с несколькими ложными путями и длинной общей траекторией к цели, что может затруднить начальное исследование. Несмотря на эти факторы, результаты в Таблице III показать некоторые из лучших результатов среди трех сценариев. В большинстве случаев управляемые команды достигают наивысшего результата, а единственные отклонения составляют в среднем менее одного дополнительного вмешательства или шага пути.
V Заключение
Мы представили менеджера, который осуществлял надзор за группами RL-агентов, выполняющих задачу навигации в сеточных средах. Эти сеточные среды включали состояния, указывающие на рискованные области, которых агенты должны избегать. Наша модель менеджера обучалась и тестировалась с разнообразными группами агентов. В группы входили агенты, обученные перемещаться по среде по кратчайшим путям, избегая при этом рискованных состояний. Избегая рискованных состояний, навигационные агенты формировали пути к целевому состоянию, которые могли отклоняться от кратчайших возможных. Менеджеры использовали собственную концепцию/меру риска для определения предпочтительного делегирования агентов. Разделяя понятие/модель риска для агентов и менеджеров, мы продемонстрировали, как наша модель может поддерживать группы разнородных агентов, а также показали, как наш менеджер может осуществлять надзор, не полагаясь на знание мер желаемого поведения агентов. Мы провели тестирование нашей модели менеджера, сравнив её производительность с оптимальной моделью поведения. Оптимальность определялась минимизацией длины путей и частоты вмешательства менеджера. Тестирование показало высокую эффективность менеджера, причём в большинстве случаев результаты соответствовали оптимальным или были близки к ним..
Литература
- [1] М. Кэрролл, Р. Шах, М. К. Хо, Т. Гриффитс, С. Сешиа, П. Аббил и А. Драган, «О пользе изучения человека для координации взаимодействия человека и ИИ»,” Достижения в области нейронных систем обработки информации, т. 32, 2019.
- [2] М. Чен, С. Николаидис, Х. Со, Д. Хсу и С. Шриниваса, «Планирование с учетом доверия для взаимодействия человека и робота», в Труды международной конференции ACM/IEEE по взаимодействию человека и робота 2018 года, 2018, стр. 307–315.
- [3] З. Р. Хавас, С. Р. Ахмадзаде и П. Робинетт, «Моделирование доверия в человеко-роботическом взаимодействии: обзор», в Социальная робототехника, А. Р. Вагнер, Д. Фейл-Зайфер, К. С. Харинг, С. Росси, Т. Уильямс, Х. Хе и С. Сэм Гэ, ред. Шам: Springer International Publishing, 2020, с. 529–541.
- [4] С. Уэстби и К. Риедл, «Коллективный интеллект в командах человек-ИИ: байесовский подход к теории сознания», в Труды конференции AAAI по искусственному интеллекту, т. 37, № 5, 2023, с. 6119–6127.
- [5] С. А. У, Р. Э. Ван, Дж. А. Эванс, Дж. Б. Тененбаум, Д. К. Паркс и М. Клейман-Вайнер, «Слишком много поваров: Байесовский вывод для координации мультиагентного взаимодействия,” Темы в когнитивной науке, т. 13, № 2, с. 414–432, 2021.
- [6] У. Агудо, К. Г. Либерал, М. Арресе и Х. Матуте, «Влияние ошибок ИИ в процессе с участием человека»,” Когнитивные исследования: принципы и приложения, т. 9, № 1, с. 1, 2024.
- [7] Á. A. Кабрера, A. J. Друк, J. I. Хонг и A. Перер, «Обнаружение и проверка ошибок ИИ с помощью краудсорсинговых отчетов о сбоях»,” Труды ACM по взаимодействию человека и компьютера, т. 5, № CSCW2, с. 1–22, 2021.
- [8] К. Хеглер, Р. Цернеке, А. М. Клеманн, Й. Альбрехт, О. Поллатос, Х. Брюкманн и М. Визманн, «No fear no risk! Поведение человека при принятии риска зависит от хемосенсорных сигналов тревоги»,” Нейропсихология, т. 48, № 13, с. 3901–3908, 2010.
- [9] А. Махмуд, Дж. В. Фун, И. Вон и Ч.-М. Хуанг, «Искреннее признание ошибок: стратегии минимизации ошибок ИИ», в Труды конференции CHI 2022 по вопросам человеческого фактора в вычислительных системах, 2022, стр. 1–11.
- [10] Дж. Ризон, Человеческая ошибка. Издательство Кембриджского университета, 1990.
- [11] С. Рассел, И. С. Московиц и А. Раглин, «Взаимодействие человека с информацией, искусственный интеллект и ошибки».,” Автономность и искусственный интеллект: угроза или спасение?, с. 71–101, 2017.
- [12] Дж. Афанадор, М. Батиста и Н. Орен, «Алгоритм делегирования на основе состязательного подхода», в Технологии соглашений: 6-я Международная конференция, AT 2018, Берген, Норвегия, 6–7 декабря 2018 г., переработанные избранные труды 6. Шпрингер, 2019, с. 130–145.
- [13] Г. Чен, X. Ли, C. Сун и Х. Ван, «Learning to make adherence-aware advice,” Препринт arXiv:2310.00817, 2023.
- [14] А. Фукс, А. Пассарелла и М. Конти, «Оптимизация делегирования в гибридных командах человек-ИИ», 2024.
- [15] ——, “Когнитивная структура для делегирования между подверженными ошибкам ИИ и человеческими агентами," в 2022 IEEE International Conference on Smart Computing (SMARTCOMP). IEEE, 2022, стр. 317–322.
- [16] ——, “Компенсация сенсорных сбоев через делегирование в гибридных системах "человек–ИИ",” Сенсоры, т. 23, № 7, с. 3409, 2023.
- [17] ——, “оптимизация делегирования между человеческими и искусственными интеллектуальными агентами-коллабораторами," в Семинар по гибридному человеко-машинному обучению и принятию решений, 2023.
- [18] C. C. Aggarwal, «Обучение на основе экземпляров: обзор».” Классификация данных: алгоритмы и приложения, т. 157, 2014.
- [19] Р. С. Саттон и А. Г. Барто, Обучение с подкреплением: Введение. MIT Press, 2018.
- [20] Ф. М. Гарсия, К. Нота и П. С. Томас, «Обучение повторно используемым опциям для многозадачного Reinforcement Learning»,” Препринт arXiv:2001.01577, 2020.
- [21] Дж. Эрскин и К. Ленерт, «Разработка кооперативных стратегий для многоэтапных задач обучения с подкреплением»,” IEEE Robotics and Automation Letters, т. 7, № 3, с. 6590–6597, 2022.
- [22] Дж. Чакраворти, Н. Уорд, Дж. Рой, М. Шевалье-Буавье, С. Басу, А. Лупу и Д. Прекуп, «Option-Critic в кооперативных многопользовательских системах»,” Препринт arXiv:1911.12825, 2019.
- [23] Дж. Чен, М. Халием, Т. Лан и В. Аггарвал, «Метод обнаружения опций с глубоким покрытием в многоагентных системах»,” arXiv препринт arXiv:2210.03269, 2022.
- [24] К. Курцер, Ч. Чжоу и Й. М. Цёлльнер, «Децентрализованное кооперативное планирование для автоматизированных транспортных средств с использованием иерархического поиска по дереву методом Монте-Карло», в 2018 IEEE симпозиум по интеллектуальным транспортным средствам (IV). IEEE, 2018, pp. 529–536.
- [25] К. П. Лау, М.-Л. Ли и У. Хсу, «Coordination guided reinforcement learning» в AAMAS, 2012, стр. 215–222.
- [26] К. Менда, Ю.-К. Чен, Дж. Грана, Дж. У. Боно, Б. Д. Трейси, М. Дж. Кочендерфер и Д. Уолперт, «Глубокое обучение с подкреплением для событийно-управляемых многопользовательских процессов принятия решений»,” IEEE Transactions on Intelligent Transportation Systems, т. 20, № 4, с. 1259–1268, 2018.
- [27] К. Роханиманеш и С. Махадеван, «Обучение принятию параллельных действий,” Достижения в области нейронных систем обработки информации, т. 15, 2002.
- [28] А. Дж. Сингх, А. Кумар и Х. К. Лау, «Иерархическое обучение с подкреплением для многоагентных систем в управлении морским трафиком», 2020..
- [29] М. Ян, Дж. Чжао, Х. Ху, В. Чжоу и Х. Ли, «Ldsa: Обучение динамическому распределению подзадач в кооперативном многопользовательском обучении с подкреплением»,” Препринт arXiv:2205.02561, 2022.
- [30] A. Jacq, J. Ferret, O. Pietquin и M. Geist, «Lazy-MDPs: Towards Interpretable RL by Learning When to Act», в Труды 21-й Международной конференции по автономным агентам и мультиагентным системам, 2022, стр. 669–677.
- [31] В. Б. Мелеш, А. Де, А. Сингл и М. Гомес-Родригес, «Обучение переключению между машинами и людьми»,” CoRR, vol. abs/2002.04258, 2020. [Online]. Доступно: https://arxiv.org/abs/2002.04258
- [32] Е. Страйтури, А. Сингла, В. Б. Мерешт и М. Гомес-Родригес, «Reinforcement learning under algorithmic triage,” CoRR, vol. abs/2109.11328, 2021. [Online]. Доступно: https://arxiv.org/abs/2109.11328
- [33] Д. Ричардс и А. Стедмон, «Делегировать или не делегировать: обзор систем управления для автономных автомобилей»,” Прикладная эргономика, т. 53, стр. 383–388, 2016.
- [34] С. Палмер, Д. Ричардс, Г. Шелтон-Рейнер, К. Иззетоглу и Д. Инч, «Оценка переменных уровней делегированного контроля – новый метод измерения доверия», в HCI International 2020 – Поздние публикации: Когнитивные процессы, обучение и игры: 22-я Международная конференция HCI International, HCII 2020, Копенгаген, Дания, 19–24 июля 2020, Труды конференции 22. Шпрингер, 2020, с. 202–215.
- [35] C. Candrian и A. Scherer, «Восстание машин: Делегирование решений автономному ИИ,” Компьютеры в поведении человека, т. 134, с. 107308, 2022.