YOLO26: Анализ сквозной структуры для детектирования объектов в реальном времени без использования NMS
Аннотация
Фреймворк "You Only Look Once" (YOLO) долгое время служил эталоном для обнаружения объектов в реальном времени, однако традиционные версии (от YOLOv1 до YOLO11) остаются ограниченными задержками и чувствительностью к гиперпараметрам при постобработке методом Non-Maximum Suppression (NMS). В данной работе представлен всесторонний анализ YOLO26, архитектура, которая кардинально переопределяет данную парадигму, исключая NMS в пользу собственной сквозной стратегии обучения. В данном исследовании рассматриваются ключевые инновации, обеспечивающие этот переход, в частности, введение MuSGD оптимизатор для стабилизации легковесных архитектур, СТАЛ для назначения с учетом малых целей, и ProgLoss для динамического контроля. Систематический анализ официальных эталонных показателей производительности демонстрирует, что YOLO26 устанавливает новый парето-фронт, превосходя широкий спектр предшественников и современных конкурентов (включая RTMDet и DAMO-YOLO) как по скорости вывода, так и по точности детектирования. Анализ подтверждает, что за счёт разделения обучения представлений от эвристической постобработки YOLOv26 успешно преодолевает исторический компромисс между задержкой и точностью, обозначая следующий эволюционный этап в компьютерном зрении для периферийных устройств..
Ключевые слова: YOLOv26, End-to-End обнаружение объектов, без NMS, MuSGD, ProgLoss, компьютерное зрение в реальном времени, You Only Look Once.
1 Введение
Компьютерное зрение быстро эволюционировало от базовых методов обработки изображений, таких как выделение границ и морфологическая фильтрация, до области, где доминирует глубокое обучение. В авангарде этой эволюции находится задача обнаружения объектов — фундаментальная задача идентификации и локализации семантических объектов в цифровом изображении. В отличие от простой классификации, которая присваивает изображению единую метку, обнаружение объектов требует одновременного предсказания меток классов и геометрических ограничивающих рамок. Эта возможность является краеугольным камнем современной автоматизации, лежащим в основе критически важных приложений — от автономного вождения и навигации роботов до анализа медицинских изображений и систем реального наблюдения. По мере роста спроса на анализ в реальном времени область сместилась от вычислительно сложных двухэтапных детекторов (таких как Faster R-CNN) в сторону эффективных одноэтапных архитектур, которые делают упор на скорость вывода без ущерба для точности..
1.1 Наследие Ultralytics
В этой области Ultralytics стала определяющей силой в области детекции в реальном времени. Начиная со стандартизации архитектуры YOLO (You Only Look Once), Ultralytics последовательно расширяла границы эффективности. Их итеративные релизы — наиболее заметные YOLOv5 и YOLOv8 — установили новый отраслевой стандарт, объединяя Cross-Stage Partial (CSP) backbone с удобными для пользователя конвейерами развертывания. Эти модели успешно демократизировали ИИ, позволяя выполнять сложные задачи детекции на периферийных устройствах с ограниченными вычислительными ресурсами. Однако даже эти передовые модели в значительной степени полагались на постобработку Non-Maximum Suppression (NMS) — последовательный этап, который вносит вариативность задержек в условиях плотных сцен..
1.2 YOLOv26: Самая быстрая модель обнаружения объектов
Выпущенный в Сентябрь 2025, YOLOv26 устанавливает новый рубеж в истории детектирования объектов в реальном времени. Для количественной оценки этого скачка, Команда Ultralytics опубликовал официальные тестовые показатели, сравнивающие YOLOv26 с комплексным набором предшественников (YOLOv5 [16] через YOLO11 [18, 5]) и конкурентоспособные архитектуры, такие как RTMDet [34], DAMO-YOLO [49], и PP-YOLOE+ [48].
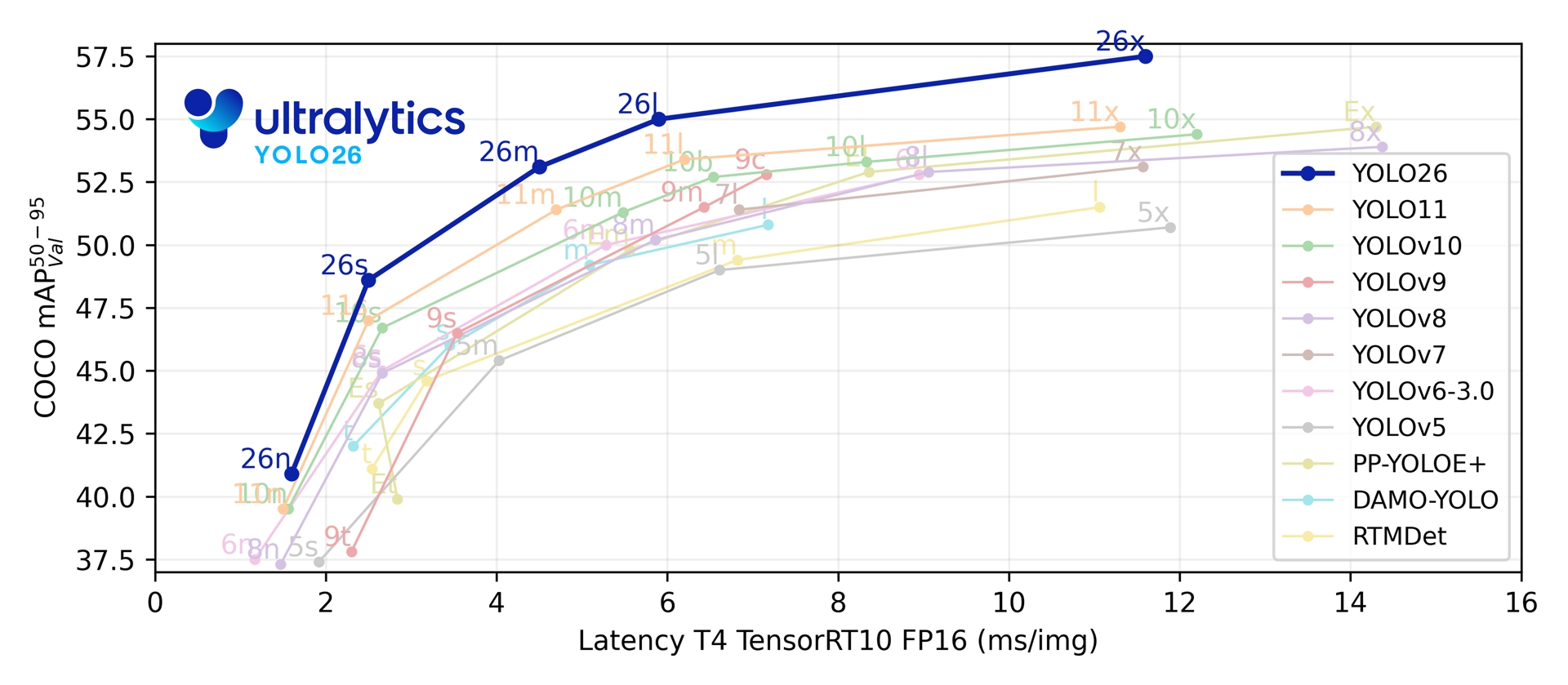
1.2.1 Анализ заявленной производительности
Как показано в официальных данных (Рисунок 1) [19], ландшафт производительности определяется семейством YOLOv26.
-
•
Парето-доминирование: Зарегистрированные метрики показывают, что кривая YOLOv26 находится строго выше и левее всех остальных моделей. [18]. Это означает, что для любого заданного бюджета задержки данная архитектура обеспечивает более высокую точность; и наоборот, для любой целевой точности она обеспечивает максимальную скорость вывода..
-
•
Масштабирование от Nano до Extra-Large: Бенчмарки Ultralytics демонстрируют доминирование во всех масштабах моделей. [18]. Нано-вариант (26n) показано, что достигает mAP при пренебрежимо малой задержке в На высоком уровне производительности, сверхбольшая модель (26x) расширяет границы точности до средняя точность (mAP) при сохранении работы в реальном времени ( мс), превосходя как YOLO11x [18] и RTMDet [34].
Эмпирические данные, предоставленные разработчиками, подтверждают, что удаление NMS и внедрение архитектуры End-to-End эффективно обеспечили прирост исходной пропускной способности, закрепив статус YOLOv26 как самого быстрого детектора из существующих..
1.3 Вклад данной статьи
Данное исследование представляет всесторонний анализ архитектуры YOLOv26, оценивая её влияние на современное состояние задач обнаружения объектов в реальном времени. Основные вклады данной статьи суммируются следующим образом::
-
•
Архитектурная деконструкция: В данной статье представлен детальный анализ архитектуры Native End-to-End NMS-Free, объясняющий математические механизмы, позволяющие исключить недифференцируемую постобработку..
-
•
Анализ динамики обучения: Рассмотрены новые стратегии оптимизации—в частности, MuSGD, STAL и ProgLoss—чтобы прояснить, как они обеспечивают устойчивую сходимость для облегчённых сквозных архитектур..
-
•
Сравнительный анализ производительности: Представлено сравнительное исследование YOLOv26 с предыдущими версиями (YOLOv1–v11), демонстрирующее новый фронт Парето, сформированный компромиссом между скоростью и точностью в семействе YOLO..
-
•
Оценка воздействия: Обсуждаются последствия устранения "экспортного разрыва" с анализом того, как детерминированная задержка повышает безопасность критически важных периферийных приложений..
1.4 Организация статьи
Остальная часть статьи структурирована следующим образом:: Раздел 2 прослеживает историческую эволюцию линейки YOLO, задавая контекст для текущего архитектурного сдвига. Раздел 3 анализирует ключевые инновации YOLOv26, включая NMS-Free pipeline, DFL-free decoupled head и динамику обучения MuSGD. Раздел 4 подробно описывает унифицированные возможности модели в решении множества задач, включая детекцию, сегментацию и оценку позы.. Раздел 5 анализирует ключевую проблему "экспортного разрыва" и то, как архитектура обеспечивает детерминированную задержку на периферийном оборудовании. Раздел 6 предлагает перспективные направления для исследований, такие как внутренняя объясняемость и пространственно-временное восприятие. Наконец,, Раздел 7 обобщает вклад и потенциальное влияние данной работы.
2 Эволюция YOLO
Семейство YOLO (You Only Look Once) прошло десятилетие быстрой архитектурной эволюции, перейдя от жесткого детектирования на основе сетки к гибкому, многозадачному интеллекту. Этот прогресс можно разделить на три отдельных эры: Эру Основ (v1–v3), Эру Расширения Сообщества (v4–v7) и Современную Эру Унификации (v8–v26). Каждая эра определяется изменением в способе извлечения пространственных признаков и методах обучения итоговых предсказаний..
2.1 Фундаментальная эпоха (2015–2018)
Оригинальный YOLOv1 [36] революционизировал обнаружение объектов, переформулировав его как единую задачу регрессии, пожертвовав частью точности локализации ради скорости работы в реальном времени. Последующие итерации, такие как YOLOv2, ввели анкерные ящики. [37] для улучшенного воспроизведения и многоуровневых пирамид признаков в YOLOv3 [38] для решения "проблемы малых объектов", утвердив Darknet в качестве отраслевого стандарта. Эта эпоха характеризовалась переходом от полностью связанных слоёв к полностью свёрточным архитектурам, заложив основу для глобального контекстного анализа в одноэтапных детекторах..
2.2 Эпоха расширения сообщества (2020–2022)
Этот период ознаменовался диверсификацией линейки YOLO, возглавляемой YOLOv4. [1] и YOLOv5 [16], который представил CSP-соединения (Cross-Stage Partial) и усовершенствованные методы аугментации "Bag-of-Freebies". Эта эпоха ознаменовала переход к готовым к производству фреймворкам, включая такие варианты, как YOLOv6. [25] и YOLOv7 [45] введение репараметризации и архитектур E-ELAN для максимизации использования вычислительных ресурсов с учетом специфики оборудования. Благодаря интеграции мозаичной аугментации и генетической оптимизации якорей эти модели устранили разрыв между академическими исследованиями и промышленным внедрением на различных аппаратных платформах..
2.3 Современная эпоха унификации (2023–настоящее время))
Начиная с YOLOv8 [15], акцент сместился в сторону anchor-free подходов с разделёнными головками. Эта архитектурная модульность была дополнительно усовершенствована в YOLOv9. [46] через Programmable Gradient Information (PGI) и в YOLOv10 [44], который ввел согласованное двойное назначение меток для обучения без NMS. Линия продолжилась с YOLO11 [18, 6], оптимизация основы C3k2 для многозадачной эффективности и YOLOv12 [43], который интегрировал механизм Area Attention () обеспечить контекст уровня Transformer на скоростях CNN. В последнее время YOLOv13 [24] использовали гиперграфовое пространственное моделирование для улучшения реляционных рассуждений в сложных сценах. Этот переход отражает более широкую тенденцию к отказу от ручных эвристик в пользу сквозных дифференцируемых конвейеров, прокладывая путь для оптимизированных для периферийных устройств стратегий, наблюдаемых в последних итерациях..
Ключевой вызов, выявленный в эту эпоху, заключается в "Экспортный разрыв"—снижение производительности, наблюдаемое при переносе модели из среды обучения на GPU на оборудование для инференса на периферийных устройствах (NPU/CPU). Сложные операторы, такие как Distribution Focal Loss (DFL), используемые в версиях с v8 по v13 [15, 44, 24], хотя и точные, часто создают узкие места по задержкам на аппаратном обеспечении с целочисленной арифметикой.
YOLO26 [19] ознаменует кульминацию этой линии развития, отходя от тенденций, ориентированных на сложность в версиях v12 и v13, чтобы сделать приоритетом задержки на периферийных устройствах. Устраняя вычислительную нагрузку, связанную с DFL, и внедряя нативный одноэтапный head предсказания, YOLO26 достигает детерминированного времени вывода, что делает его высокоэффективным для развертывания в реальном времени на маломощных устройствах. Эти архитектурные изменения суммированы в Таблице 1.
| Модель | Основная архитектура | Шея | Голова | Задача(и) | Anc-hors | Потери | Постобработка. | Ключевые инновации и вклад |
|
YOLOv1
(2015) |
Darknet-24 | [[ERROR]] None... | Связанные | Обнаружение объектов | Нет | SSE (Sum of Squared Errors)) | NMS | Унифицированная одноэтапная регрессионная структура, обеспечивающая детектирование объектов в реальном времени. |
|
YOLOv2
(2016) |
Darknet-19 | Сквозной проход | Связанный | Обнаружение объектов | Да | Сумма квадратов ошибок (SSE) | NMS (Non-Maximum Suppression) | Введены якорные блоки, пакетная нормализация и сквозной слой для улучшения полноты и детектирования мелких объектов.. |
|
YOLOv3
(2018) |
Darknet-53 | Мультимасштабный | Связанный | Обнаружение объектов | Да | BCE + SSE | NMS (Non-Maximum Suppression) | Многомасштабная стратегия предсказания признаков для улучшенной локализации малых объектов. |
|
YOLOv4
(2020) |
CSPDarknet53 | PAN | Связанный | Обнаружение объектов | Да | CIoU + BCE | NMS | CSP-интегрированное увеличение для оптимального компромисса между скоростью и точностью. |
|
YOLOv5
(2020) |
CSPDarknet | ПАН | Связанные | Обнаружение объектов | Да | GIoU/CIoU + BCE | NMS (Non-Maximum Suppression) | Модульная архитектура на основе PyTorch с автоматической оптимизацией якорей для простого развертывания. |
|
YOLOv6
(2022) |
EfficientRep | PAN | Развязанный | Обнаружение объектов | Да | SIoU / Varifocal | NMS (Non-Maximum Suppression) | Репараметризованная свертка для повышения эффективности промышленного вывода с высокой пропускной способностью. |
|
YOLOv7
(2022) |
E-ELAN | CSP-PAN | Ведущий + Вспомогательный | Обнаружение объектов | Да | CIoU + BCE | NMS | Представлены E-ELAN, глубокий надзор и назначение OTA для повышения точности и эффективности.. |
|
YOLOv8
(2023) |
C2f | PAN | Развязанный | Обнаружение объектов, сегментация, оценка позы. | Нет | BCE + CIoU + DFL | NMS (Non-Maximum Suppression) | Безанкерная декомбинированная головка, обеспечивающая унифицированную мультизадачную систему детектирования.. |
|
YOLOv9
(2024) |
GELAN | PAN | Развязанный | Обнаружение объектов | Нет | BCE + CIoU + DFL | NMS (Non-Maximum Suppression) | Программируемая информация о градиенте и GELAN для преодоления информационного узкого места в глубоких сетях. |
|
YOLOv10
(2024) |
GELAN | ПАН | Разъединённый | Обнаружение объектов | Нет | BCE + CIoU + DFL | NMS-Free | Безинференсный вывод без NMS через двойное назначение меток; интеграция частичного самовнимания в GELAN. |
|
YOLOv11
(2024) |
C3k2 | PAN | Развязанный | Обнаружение объектов, сегментация, оценка позы. | Нет | BCE + CIoU + DFL | NMS (Non-Maximum Suppression) | Уточнение признаков на основе C2PSA; по-прежнему использует стандартный NMS для постобработки.. |
|
YOLOv12
(2025) |
Flash Backbone + Area Attention | PAN | Разъединённый | Обнаружение объектов, сегментация | Нет | BCE + CIoU + DFL | NMS | Область применения Attention () для захвата долгосрочных зависимостей при сохранении вычислительной эффективности; улучшает производительность при решении множественных задач. |
|
YOLOv13
(2025) |
Гипер-Сеть | ПАН | Развязанный | Обнаружение объектов, сегментация, оценка позы | Нет | BCE + CIoU + DFL | NMS (Non-Maximum Suppression) | Сторонний релиз от iMoonLab; гиперграфовое пространственное моделирование для реляционных рассуждений и понимания сложных сцен. |
|
YOLOv26
(2026) |
CSP-Muon (Edge-Optimized CNN) | ПАН | Развязанный (1-к-1) | Обнаружение объектов, сегментация, оценка позы, OBB | Нет | STAL + ProgLoss | NMS-Free | Оптимизированное для периферийных устройств обучение без DFL с назначением меток один-к-одному; встроенный модуль без NMS для развертывания с низкой задержкой; оптимизировано для экспорта на CPU и периферийные устройства.. |
3 Архитектура и методология YOLOv26
Архитектурная философия YOLOv26 отклоняется от современной тенденции увеличения сложности параметров (как это наблюдается в v10 и v11).)[18] сосредоточиться на вычислительная плотность и детерминированная задержка. Это достигается за счет перестройки конвейера вывода для устранения эвристических узких мест и применения стратегий оптимизации, традиционно используемых для LLM, таких как MuSGD..
3.1 Нативная сквозная архитектура без NMS
Традиционные детекторы объектов используют Non-Maximum Suppression (NMS) в качестве отдельного этапа постобработки для фильтрации избыточных ограничивающих рамок. NMS работает путем итеративного выбора предложения с наивысшей оценкой достоверности. () и подавление всех остальных перекрывающихся рамок () чей показатель Intersection over Union (IoU) с превышает предопределённый порог (). Данный процесс может быть формально определен как [2]:
| (1) |
где является текущим bounding box с максимальной уверенностью и обновлённый счёт. Этот эвристический метод по своей природе последователен, что создаёт узкое место в виде задержки, варьирующейся в зависимости от плотности сцены (т.е. количества обнаруженных объектов).
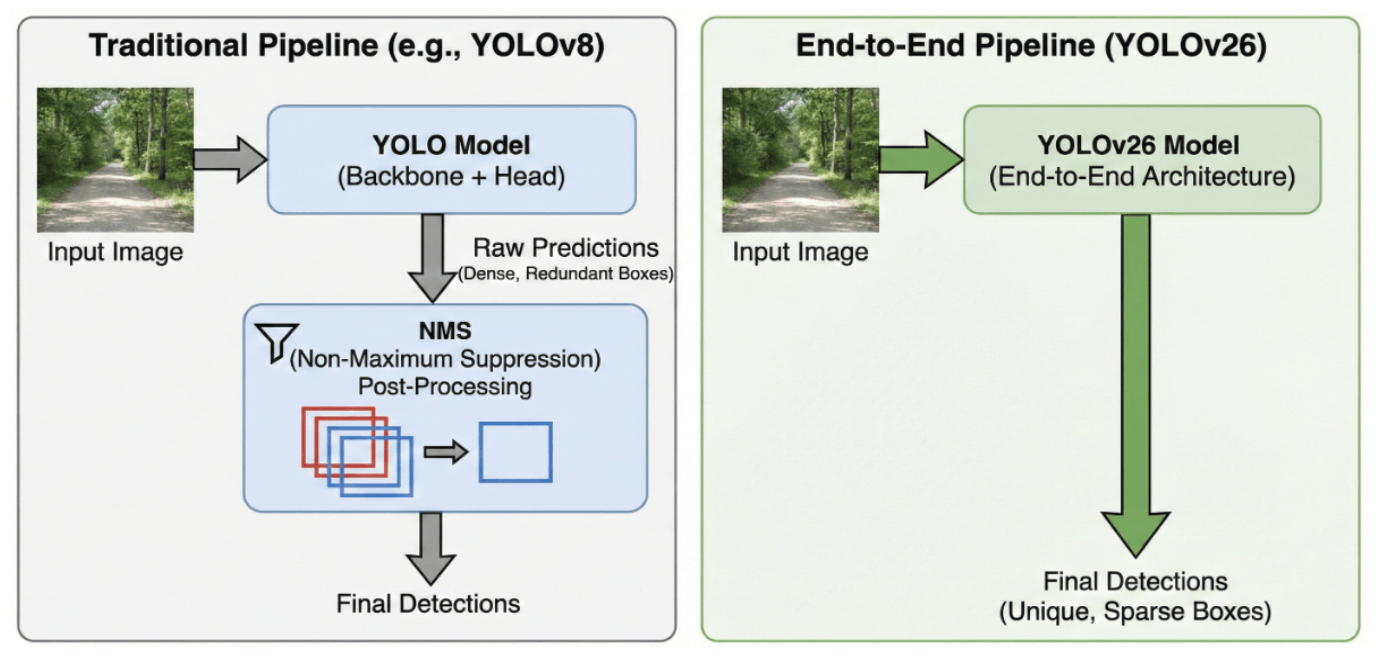
YOLOv26 принципиально изменяет этот конвейер за счет Нативная сквозная архитектура. Путем перепроектирования головы предсказания для поддержки однозначное соответствие меток [44], модель обучается выводить единый, окончательный bounding box для каждого экземпляра объекта в процессе обучения. Это изменение архитектуры устраняет необходимость в Eq. 1 полностью, преобразуя логический вывод из многоэтапной операции фильтрации в прямое детерминированное отображение входа на выход (см. рис.. 2). Результатом является облегчённый и оптимизированный граф выполнения, который проще развернуть и который обеспечивает постоянную задержку независимо от количества объектов. [34].
Влияние на производительность: Удаление оператора NMS приводит к значительному снижению задержек, особенно на оборудовании без GPU, где последовательные операции создают узкие места. Переход к этой сквозной парадигме позволил Ultralytics сообщить, что YOLOv26 достигает ускорения вывода приблизительно 43% на CPU-целях по сравнению с базовыми подходами на основе стандартного NMS [19]. Такое постоянное время вывода критически важно для приложений, связанных с безопасностью, например, автономного вождения или медицинского мониторинга, где требуются детерминированные времена отклика независимо от сложности сцены..
3.2 Регрессионно-центрированная декомбинированная головка (без DFL))
Последние версии YOLO (v8–v11) [18]) принята функция потерь Distribution Focal Loss (DFL) [27] моделировать координаты ограничивающих рамок как общие распределения, а не детерминированные значения. Хотя DFL повышает точность локализации за счёт учёта неопределённости на границах объектов, он вносит значительные вычислительные затраты: необходимость выполнения операций Softmax по дискретизированным бинам для каждого предсказания координат. На специализированных периферийных аппаратных платформах (NPU и DSP) эти слои Softmax известны сложностью квантования и часто становятся основным узким местом по задержке. [11].
Количественная оценка накладных расходов Softmax: В голове на основе DFL оценка одной координаты требует интегрирования по дискретизированному распределению вероятностей (обычно 16 бинов). Это вынуждает механизм вывода вычислять взвешенную сумму Softmax для каждого параметра ограничивающего прямоугольника.:
| (2) |
Данная операция включает повторяющееся возведение в степень () и операции деления, которые требуют значительных вычислительных ресурсов на специализированных ускорителях с целочисленной арифметикой [41].
[Изображение распределения функции потерь Distribution Focal Loss (DFL) в сравнении с головками предсказания Direct Regression.]
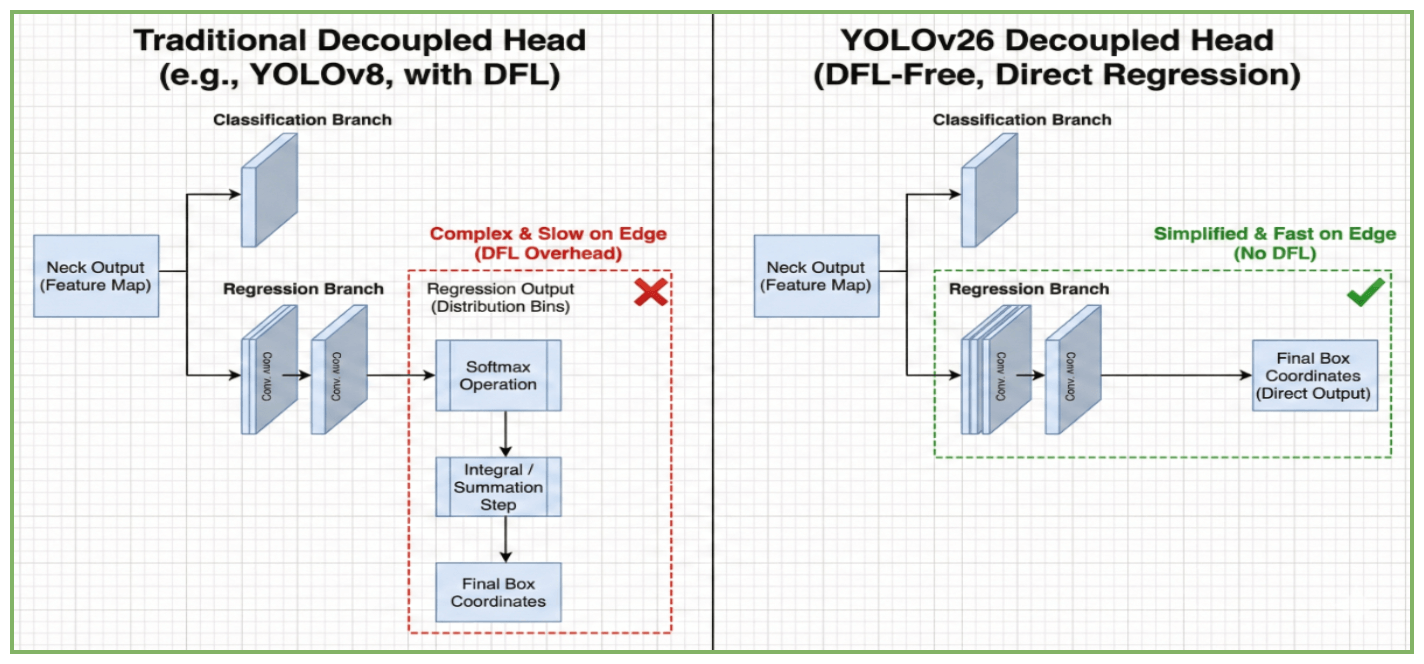
YOLOv26 возвращается к Стратегия прямой регрессии, полное удаление этого модуля (см. рис.. 3). Этот архитектурный откат обусловлен "экспортным разрывом" — расхождением между теоретическими FLOPs и фактической скоростью вывода на развернутом оборудовании. [34]. Исключая интегральное представление уравнения. 2, фаза декодирования упрощается до прямого линейного отображения:
| (3) |
Для сохранения высокой точности без преимуществ распределения DFL, YOLOv26 использует усовершенствованный Decoupled Head структура, вдохновленная YOLOX [10]. Как показано в стандартных топологиях, головной модуль разделяет извлечение признаков на два независимых направления.:
| (4) |
где предсказывает вероятности классов и предсказывает параметры регрессии bounding box напрямую. Такое разделение гарантирует, что удаление DFL не ухудшает производительность классификации. [10], в то время как регрессионная ветвь оптимизируется с помощью новых функций STAL и ProgLoss для восстановления точности локализации, утраченной из-за отказа от априорного распределения.
3.3 Продвинутые динамики обучения: MuSGD, STAL и ProgLoss
Удаление модуля Distribution Focal Loss (DFL) и переход к сквозной архитектуре требуют более надежной стратегии обучения для предотвращения коллапса градиентов. YOLOv26 решает эту задачу за счет трех ключевых инноваций в оптимизации и контроле обучения..
3.3.1 Оптимизатор MuSGD
Для обеспечения устойчивости сходимости в новой архитектуре Ultralytics сообщает, что YOLOv26 внедряет MuSGD (Momentum-Unified Stochastic Gradient Descent)), новый гибридный оптимизатор, объединяющий свойства стандартного SGD с Мюон оптимизатор. Явно вдохновленный динамикой обучения Moonshot AI’s Kimi K2 крупная языковая модель, MuSGD демонстрирует стратегический перенос передовых методов оптимизации из области NLP в компьютерное зрение [21].
Мюонная компонента: Основное новшество MuSGD заключается в интеграции оптимизатора Muon. [31]. В отличие от поэлементных оптимизаторов (например, AdamW), Muon выполняет ортогонализация матрицы, обновление всей матрицы весов с целью её ортогонализации относительно текущего состояния. Это максимизирует эффективность обновления вдоль наиболее значимых направлений при ограничении спектральной нормы [20].
Математическая формулировка: MuSGD сочетает это ортогональное масштабирование со стабильностью классического SGD. Сначала мы определяем стандартный буфер момента. используемый в Stochastic Gradient Descent:
| (5) |
где является градиентом и является коэффициентом импульса. MuSGD затем модифицирует окончательное обновление весов, внедряя ортогонализацию Ньютона-Шульца в эту траекторию.:
| (6) |
где эффективно "отбеливает" матрицу градиентов с помощью итеративного процесса уточнения [13]. Этот гибридный подход снижает дисперсию чистого SGD, избегая при этом нестабильности чисто ортогональных обновлений на начальных эпохах (см. рис.. 4).
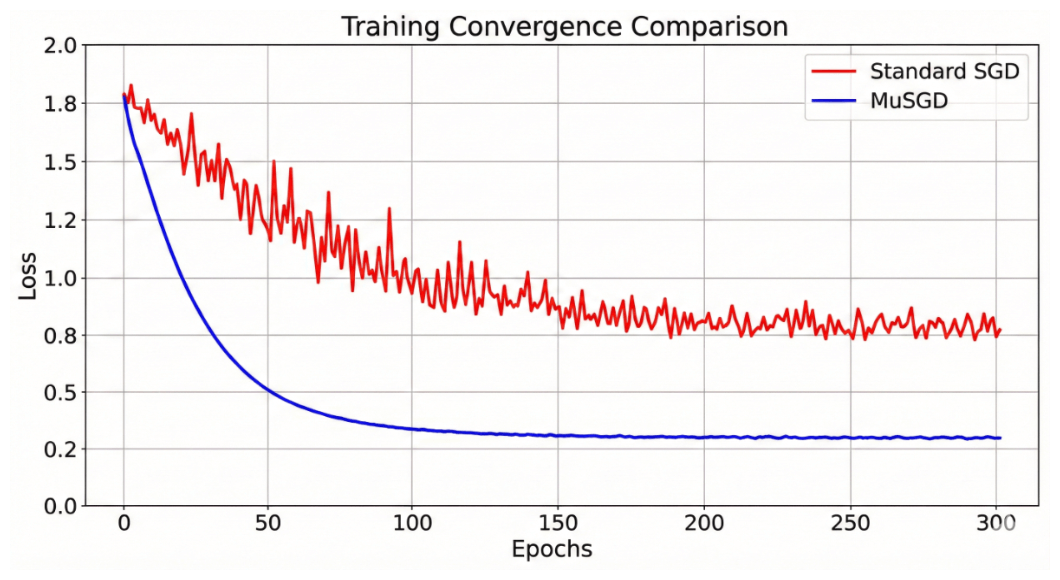
Позволяя упрощенной сквозной архитектуре обучаться устойчивым признакам без необходимости сложных процедур разогрева, MuSGD сокращает общее время обучения, необходимое для достижения сходимости..
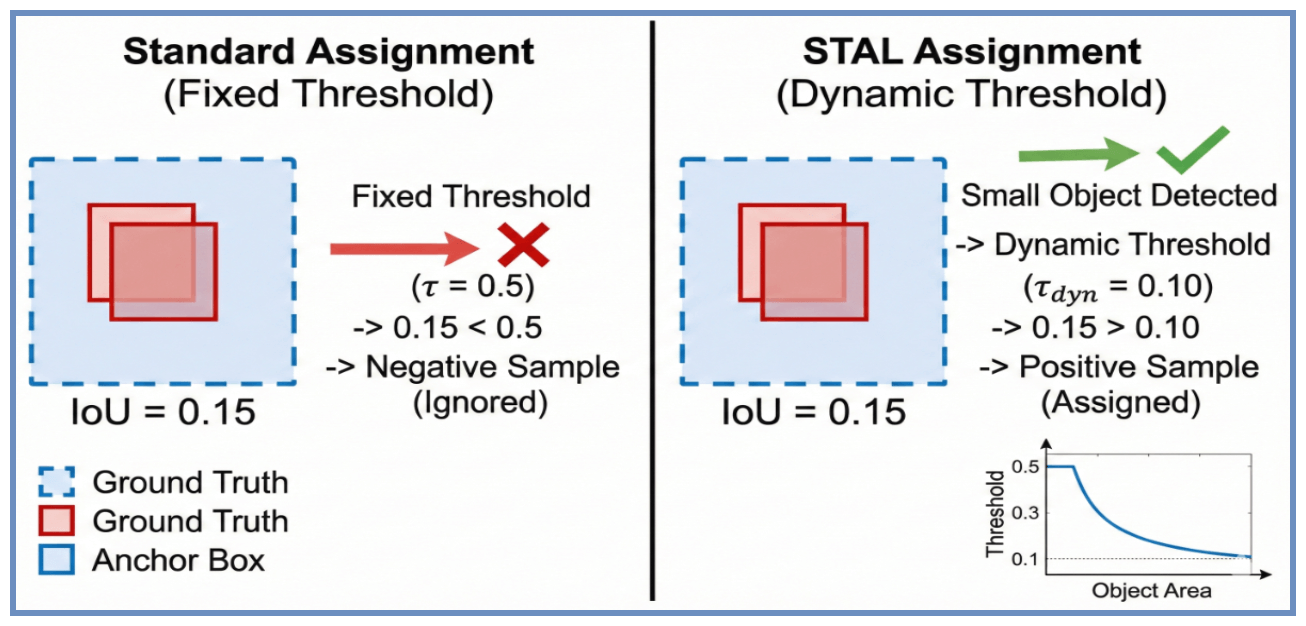
3.3.2 Метод распределения меток с учетом малых объектов (STAL)
Для решения проблемы "исчезновения мелких объектов", присущей моделям, оптимизированным для работы с границами, [23], YOLOv26 реализует Метод распределения меток с учетом малых объектов (STAL). Стандартные стратегии назначения обычно основаны на фиксированном пороге Intersection-over-Union (IoU) (например,., ). Хотя этот жесткий порог эффективен для крупных объектов, он оказывает негативное влияние на малые цели (занимающие области изображения), где даже хорошо центрированные привязки дают математически низкие показатели IoU из-за ошибок дискретизации на уровне пикселей и чувствительности метрики IoU к малым пространственным смещениям [39].
STAL решает эту проблему, заменяя статический порог динамической переменной, которая адаптируется к масштабу объекта, вдохновляясь подходом Task Alignment Learning (TAL).) [9]. Как определено в уравнении. 7, порог соответствия расслабляется по мере уменьшения относительного размера объекта:
| (7) |
где управляет скоростью затухания. Для крошечного объекта экспоненциальный член приближается к 1, существенно снижая и разрешая привязкам с меньшим физическим перекрытием оставаться положительными образцами. Это действует как "увеличительное стекло" для сигналов обучения, гарантируя, что мелкие или частично скрытые объекты — часто встречающиеся в аэрофотоснимках и медицинских сканах — получают достаточный вклад градиента. [7] (см. рис.. 5).
3.3.3 Прогрессивное балансирование потерь (ProgLoss)
Для дальнейшей стабилизации обучения сквозной архитектуры YOLOv26 использует ProgLoss, динамическая стратегия взвешивания потерь. В стандартных детекторах [15, 29], отношение между loss классификации () и функция потерь регрессии ограничивающего прямоугольника () обычно фиксирован. Однако такой статический баланс является субоптимальным для сквозного обучения, когда сеть должна одновременно обучаться дискриминации признаков и точной локализации без геометрического руководства априорных анкеров. [14].
ProgLoss решает эту проблему путем введения зависящего от времени коэффициента модуляции (). Как определено в уравнении. 8 и визуально представлено на рис.. 6, общая функция потерь изменяется в процессе обучения по эпохам :
| (8) |
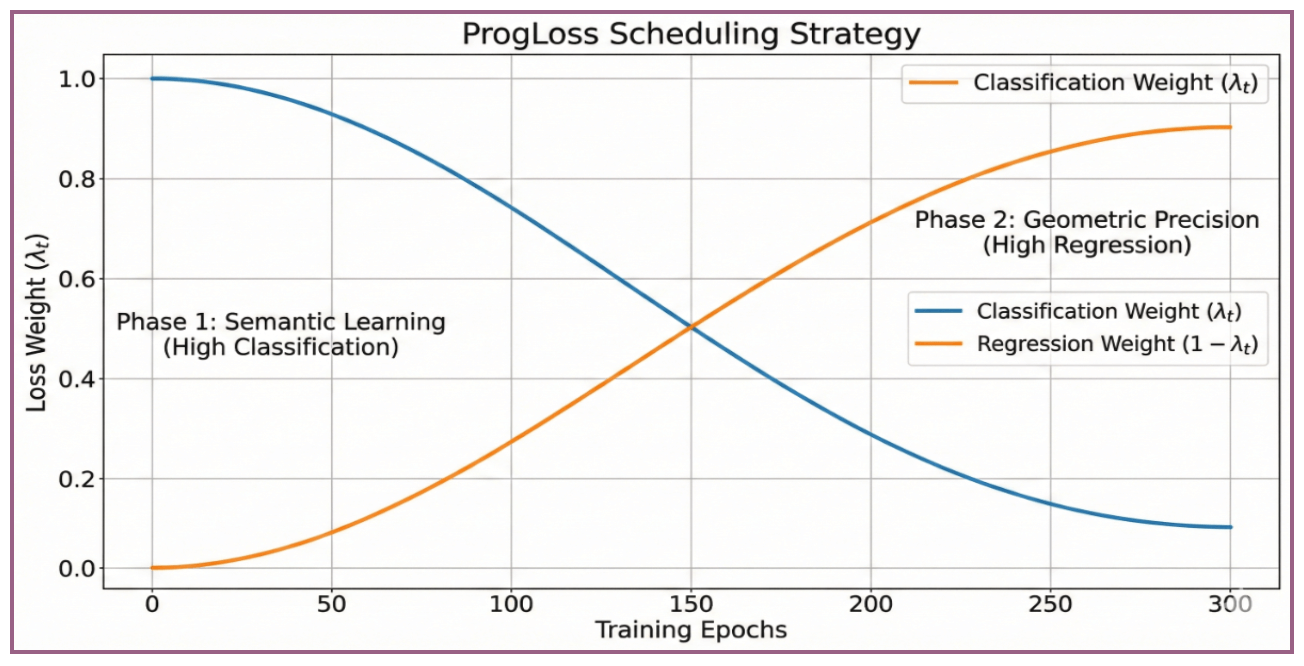
где следует монотонно убывающему расписанию, например, cosine decay [32]. Данная стратегия обеспечивает плавный переход между семантической привязкой и геометрическим уточнением.
- •
-
•
Поздняя фаза (Low ): По мере прогресса обучения (оранжевая область) акцент смещается на , позволяя модели точно настраивать геометрические границы. Это предотвращает доминирование "легких негативов" в градиенте на финальных этапах, обеспечивая высокоточную локализацию, несмотря на удаление DFL..
4 Многозадачные возможности YOLOv26
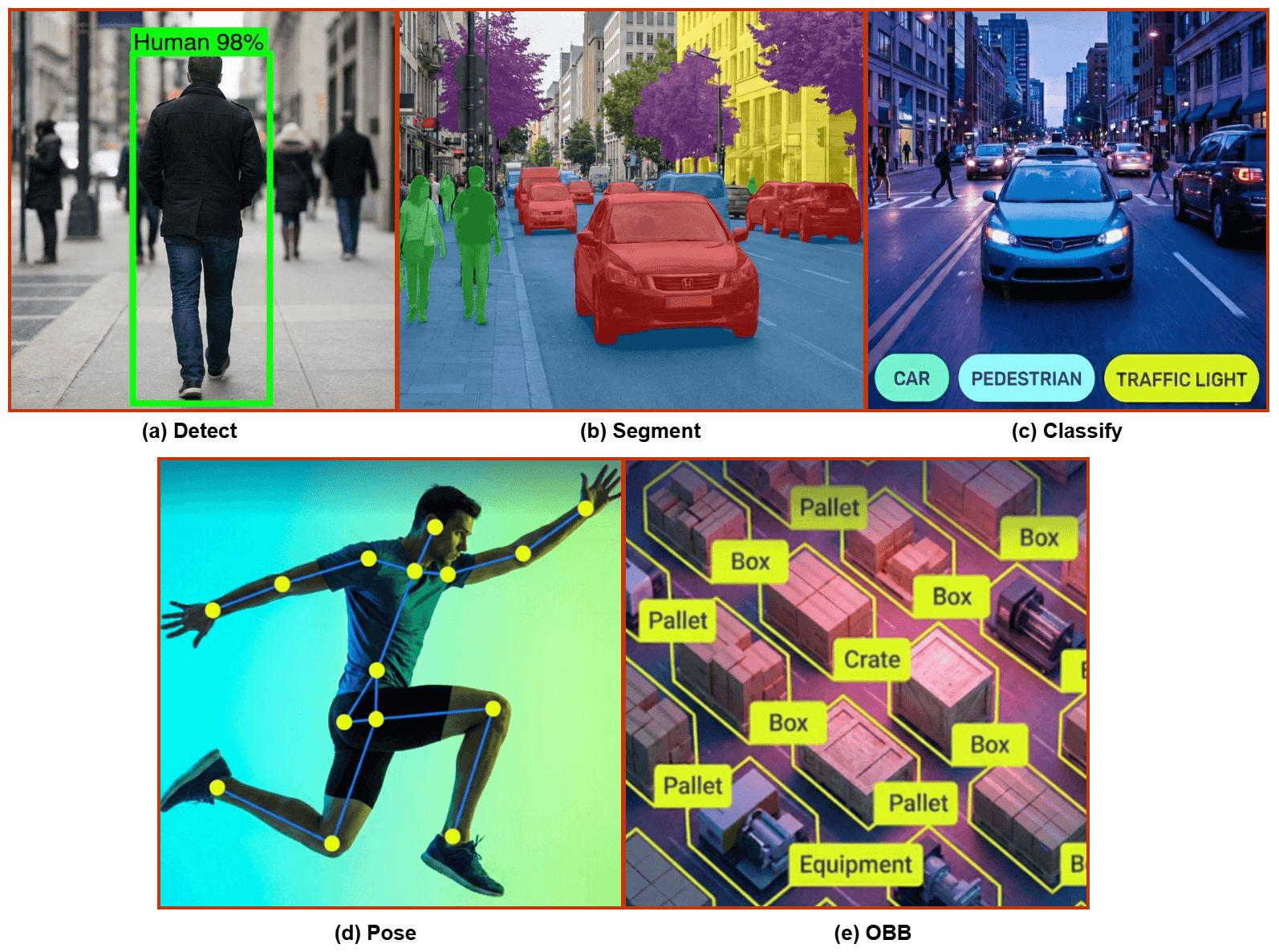
YOLOv26 функционирует как унифицированное семейство моделей, обеспечивая сквозную поддержку широкого спектра задач компьютерного зрения. [19]. Каждая архитектурная вариация, от Nano (n) до Extra-Large (x), изначально совместима со специализированными prediction heads, разработанными для различных задач пространственного и семантического анализа. Как показано на Рисунке 7, данная система выходит за рамки простого распознавания объектов, обеспечивая комплексный набор аналитических возможностей в рамках единого оптимизированного конвейера вывода.
За пределами визуального представления техническая реализация этих задач регулируется специализированными выходными структурами и функциями потерь, оптимизированными для эффективности обработки границ. Таблица 2 предоставляет сравнительное описание выходных данных головы и форматов координат, используемых в семействе YOLOv26 для сохранения архитектурной согласованности в различных областях. Эта многозадачная структура использует унифицированный backbone и упомянутое планирование ProgLoss, чтобы гарантировать, что переход от стандартных ограничивающих рамок к более сложным геометриям — таким как ключевые точки и ориентированные рамки — не приводит к значительным задержкам..
| Задача | Выходной слой (Head Output) | Формат координат | Ключевое нововведение (v26) |
|---|---|---|---|
| Обнаружение объектов | Класс + Бокс | NMS-Free, STAL Loss | |
| Сегментация экземпляров | Класс + Бокс + Маска | DFL-Free, ProgLoss | |
| Классификация | Метка класса | [[ERROR]] None... (Глобальная метка) | Глобальный пулинг, целостное представление |
| Оценка позы | Класс + Бокс + Ключевые точки | Оптимизация RLE, OKS | |
| Ориентированное обнаружение | Класс + Повернутый Прямоугольник | Angle Loss, Normalized xywhr | |
| Open-Vocabulary | Класс (Текст) + Блок | RepRTA (Folded Weights) |
4.1 Обнаружение объектов
Основная задача YOLOv26 заключается в идентификации и локализации отдельных экземпляров объектов с помощью выровненных по осям ограничивающих прямоугольников, как показано на рисунке 7(а). Хотя это остается фундаментальной задачей серии YOLO, YOLOv26 оптимизирует конвейер детектирования, используя собственную сквозную архитектуру, рассмотренную в разделе 3.1. Используя стратегию назначения меток один-к-одному, модель достигает снижения задержки процессора на 43%. [19], критический фактор для мониторинга медицинских данных в реальном времени и наблюдения на периферийных устройствах. Помимо высокой скорости, устранение недифференцируемого оператора NMS гарантирует, что процесс детектирования является полностью детерминированным. Эта предсказуемость крайне важна для достоверности методов объяснимости, обеспечивая прямой и прозрачный путь от входных пикселей до итогового вывода ограничивающих рамок..
Обнаружение мельчайших особенностей дополнительно усиливается механизмом STAL, описанным в уравнении. 7. В практических приложениях, таких как анализ микроаномалий в гистопатологических наборах данных, STAL предотвращает эффект "исчезающего градиента", характерный для малых объектов. Это позволяет YOLOv26 сохранять высокую полноту обнаружения для объектов, занимающих менее 1% площади изображения, гарантируя, что упрощенная регрессионная головка без DFL остается точной для объектов всех масштабов..
4.2 Сегментация экземпляров
Сегментация экземпляров в YOLOv26 представляет собой критический переход от региональной локализации к поточечной классификации, как показано на рисунке 7(б). Интегрируя ветвь предсказания масок наряду с разделённой головой, модель обеспечивает точное извлечение формы отдельных объектов. Как обобщено в Таблице 2, выходные данные для этой задачи включают как координаты ограничивающего прямоугольника, так и пиксельную маску (), что крайне важно для медицинской диагностики, где точная область патологии имеет большее значение, чем простая ограничивающая рамка..
Новое усовершенствование в YOLOv26-seg заключается в использовании Гранично-ориентированный контроль, поддерживается планированием ProgLoss в уравнении. 8. Поскольку модель не использует DFL, она избегает ошибок дискретизации, которые часто размывают границы объектов на периферийных устройствах. Вместо этого поздняя регрессионная фокусировка ProgLoss действует как «полировщик контуров», гарантируя сохранение четкости масок даже для мелких или перекрывающихся объектов. Благодаря способности оптимизатора MuSGD поддерживать стабильные спектральные нормы, сегментационный блок достигает более высокого разрешения признаков при меньшем количестве параметров, что приводит к ранее отмеченному ускорению на CPU и NPU. Это обеспечивает возможность высокоточной сегментации не только на высокопроизводительных GPU, но и ее полную адаптацию для работы в реальном времени на периферийных устройствах. [19].
4.3 Классификация изображений
Классификация изображений в экосистеме YOLOv26 представляет собой наиболее вычислительно эффективную задачу, поскольку она обходит необходимость пространственной регрессии или генерации масок, как показано на рисунке 7(с). Анализируя входные данные целостно, классификационный слой использует Global Average Pooling (GAP) для сжатия карт высокоуровневых признаков из базовой сети в единый вектор, который затем преобразуется в категориальные вероятности. [28]. Данная архитектура отдает приоритет общим визуальным паттернам над конкретными границами, основанными на координатах, как обобщено в Таблице 2.
Вариант YOLOv26-cls использует оптимизированную CSP-архитектуру для достижения минимальной задержки вывода, что делает его идеальным для первичной категоризации крупномасштабных медицинских или экологических наборов данных, где основным критерием является наличие патологии или объекта. [19]. Более того, интеграция ProgLoss планирование (Eq. 8) обеспечивает стабильную сходимость классификационной головы на сложных многоклассовых наборах данных. Благодаря акценту на семантическую заземленность в начальной фазе обучения модель формирует устойчивые глобальные представления, менее чувствительные к пространственному шуму или окклюзии объектов по сравнению с чисто региональными детекторами. [12].
4.4 Оценка позы
Оценка позы в YOLOv26 расширяет пространственное рассуждение до локализации 17 анатомических ориентиров, как визуализировано на Рисунке 7(d). Эта задача отслеживает ориентацию и движение суставов, выводя данные в формате триплета. для каждой ключевой точки. Конкретные анатомические индексы для стандартного отображения на основе COCO [30]. приведены в таблице 3.
| Idx | Совместный | Idx | Совместный | Idx | Совместный |
|---|---|---|---|---|---|
| 0 | Нос | 6 | Правое плечо | 12 | Правый тазобедренный сустав |
| 1 | Левый глаз | 7 | Левый локоть | 13 | Левое колено |
| 2 | Правый глаз | 8 | Правый локоть | 14 | Правое колено |
| 3 | Левое ухо | 9 | Левый запястье | 15 | Левый голеностопный сустав |
| 4 | Правое ухо | 10 | Правое запястье | 16 | Правый голеностоп |
| 5 | Левое плечо | 11 | Левый тазобедренный сустав |
Точность определяется Object Keypoint Similarity (OKS), который нормализует евклидово расстояние против масштаба объекта и константа спада для каждого соединения :
| (9) |
Для сохранения точности в отсутствие DFL, YOLOv26-pose использует Остаточное оценивание логарифмической вероятности (RLE) [26]. Моделируя пространственную неопределенность вместо фиксированного распределения, RLE позволяет модели анализировать случаи окклюзий. В сочетании с MuSGD оптимизатор, что обеспечивает высокоточную регрессию ключевых точек с детерминированной задержкой на периферийном оборудовании.
4.5 Ориентированное обнаружение объектов (OBB)
Ориентированное обнаружение объектов (OBB) в YOLOv26 включает вращательный параметр () для точной локализации перекошенных целей, как показано на Рисунке 7(е). Используя нормализованные xywhr формат, подробно описанный в Таблице 2, модель устраняет фоновый шум, характерный для выровненных по осям прямоугольников в аэросъемке и промышленных областях [8]. Для устранения ошибок разрывов на границах, присущих угловой регрессии, архитектура использует специализированный Angle Loss который сохраняет геометрическую согласованность даже для почти квадратных объектов [50].
Данная задача использует преимущества Прямая регрессия стратегия и MuSGD оптимизатор для достижения высокой угловой точности без вычислительных затрат, связанных с распределённым фокальным потерями. При развертывании на аппаратном обеспечении периферийного уровня, таком как БПЛА, Без NMS Голова обеспечивает детерминированную задержку в плотных средах, таких как порты. Эти оптимизации приводят к ускорению вывода на 43% по сравнению с традиционными эвристическими базовыми подходами на основе ротационного NMS. [19], обеспечение работы в реальном времени на устройствах с ограниченными ресурсами.
4.6 Open-Vocabulary Detection and Segmentation (YOLOE-26)
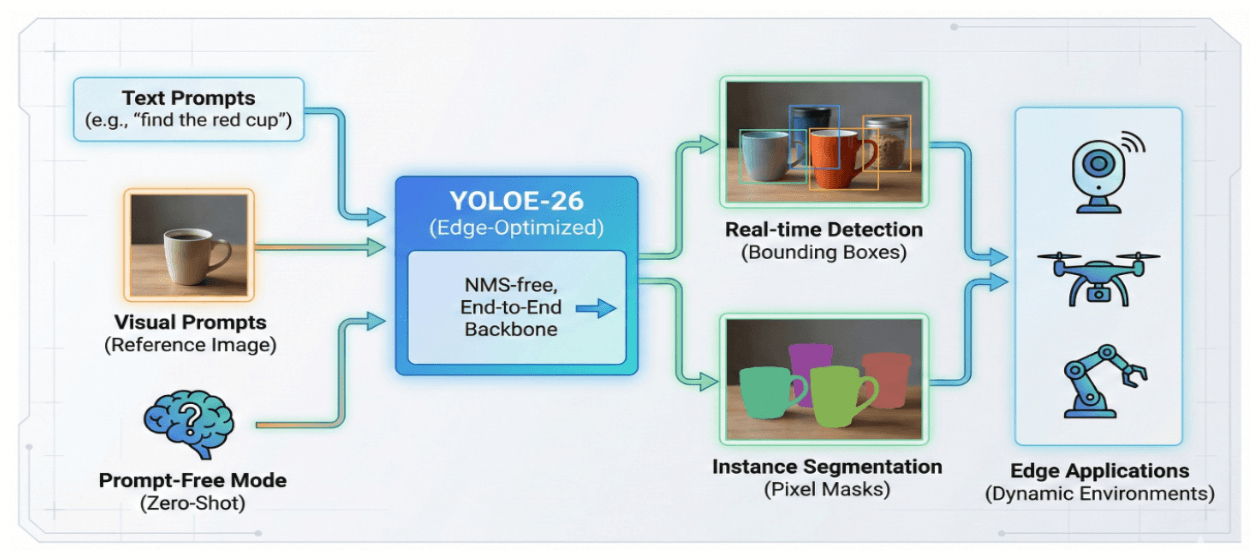
YOLOE-26 представляет собой значительное развитие в линейке моделей за счёт интеграции высокопроизводительной архитектуры YOLOv26 с расширенными возможностями открытого словаря. Благодаря согласованию визуальных признаков с богатыми лингвистическими эмбеддингами, данная функциональность обеспечивает обнаружение в реальном времени и семантическую сегментацию произвольных классов объектов, эффективно устраняя исторические ограничения обучения на фиксированных категориях. [35].
Фреймворк предоставляет гибкие варианты вывода для адаптации к динамическим сценариям. Как концептуально показано на Рисунке 8, YOLOE-26 поддерживает три различных режима: использование текстовых промптов для определения целей (например, «найди красную чашку»), применение визуальных промптов через эталонные изображения для распознавания в режиме one-shot или работу в беспромптовом режиме для zero-shot вывода..
С технической точки зрения, YOLOE-26 использует встроенные возможности архитектуры Transformer для обработки многомерных данных, сочетая методы Reinforcement Learning с оптимизатором AdamW. Модель демонстрирует улучшенную производительность в задачах нейролингвистического программирования (NLP) благодаря интеграции механизмов внимания, аналогичных BERT, но с адаптацией для работы с крупномасштабными языковыми моделями (LLM). Бесплатная NMS, сквозной дизайн основного каркаса YOLOv26. Такая конструкция устраняет необходимость эвристических постобработок, таких как Non-Maximum Suppression (NMS), что представляет собой смену парадигмы, популяризированную детекторами на основе Transformer. [3]. На основе этой оптимизированной архитектуры модель обеспечивает быстрое выполнение логического вывода в открытом мире с минимальной задержкой. Такое сочетание высокой скорости работы и семантической гибкости делает YOLOE-26 мощным решением для периферийных приложений, развертываемых в средах, где объекты интереса представляют широкий и развивающийся словарь. [19].
5 Последствия для Edge AI: преодоление "разрыва экспорта""
Распространённой проблемой в современной эпохе детектирования объектов является "Export Gap" — расхождение между теоретической производительностью, наблюдаемой во время обучения на GPU, и фактической задержкой, достигаемой на развёрнутом edge-оборудовании. [34]. В данном разделе анализируется, как YOLOv26 решает это ключевое узкое место за счёт своих архитектурных ограничений..
5.1 Узкое место задержки в традиционных моделях
Предыдущие модели State-of-the-Art (SOTA), включая YOLOv8–YOLOv13, в значительной степени полагались на Distribution Focal Loss (DFL) для максимизации mAP. [15, 44, 24]. Несмотря на математическую точность, DFL требует сложных операций Softmax над дискретизированными бинами для вычисления итоговых координат. [27]. На серверных GPU эти операции пренебрежимо малы. Однако на оборудовании с целочисленной арифметикой (например, NPU в мобильных устройствах или DSP в дронах) слои Softmax сложно квантовать, и они часто становятся основным узким местом по задержке. [11]. Следовательно, модель, демонстрирующая высокую эффективность в научной публикации, часто подвергается значительному снижению пропускной способности при переносе в реальные встраиваемые системы..
5.2 Детерминированный вывод посредством прямой регрессии
YOLOv26 решает этот компромисс, возвращаясь к стратегии Direct Regression, явно устраняя вычислительную нагрузку DFL. [17]. Отделяя обучение представлений от сложной постобработки, архитектура гарантирует, что граф вывода состоит исключительно из стандартных сверточных и линейных операций. Такой подход обеспечивает детерминированная задержка—время вывода остается постоянным независимо от сложности сцены или плотности объектов [17, 34]. Эта предсказуемость крайне важна для критически важных приложений на граничных устройствах, таких как автономное вождение и навигация роботов, где нарушения временных ограничений могут привести к катастрофическим последствиям. [17].
6 Будущие направления
Хотя YOLOv26 устанавливает новый эталон для обнаружения в реальном времени, остаются несколько направлений для исследования, чтобы полностью преодолеть разрыв между эффективностью на периферийных устройствах и когнитивным интеллектом..
Встроенная объяснимость и надежность: В настоящее время "чёрный ящик" глубинных детекторов исследуется с помощью постфактумных методов, таких как Grad-CAM. [40] или SHAP [33], которые аппроксимируют процесс принятия решений модели после вывода. Ключевым направлением будущих исследований является разработка Встроенная объясняемость [4], где детекционная головка выводит не только ограничивающий прямоугольник и класс, но также карту обоснования или текстовую аргументацию (например, "Classified as Опухоль из-за нерегулярной текстуры границ"). Встраивание интерпретируемости непосредственно в сквозной конвейер станет революционным для критически важных областей, таких как медицинская диагностика и автономные системы обороны, гарантируя, что высокоскоростные решения также будут прозрачными и проверяемыми..
Единое пространственно-временное восприятие: Детерминированная природа YOLOv26, исключающая NMS, делает его особенно подходящим для анализа видео. Традиционные детекторы часто страдают от "мерцания" в видеопотоках, поскольку NMS произвольно выбирает различные bounding box между кадрами. Будущие версии могут расширить архитектуру YOLOv26 для обработки Пространственно-временное обнаружение объектов изначально. Рассматривая время как третье пространственное измерение, модель могла выполнять отслеживание и распознавание действий (например, "человек бежит") в рамках единого прямого прохода, исключая необходимость в отдельных алгоритмах трекинга, таких как DeepSORT. [47].
Адаптация во время тестирования на периферийных устройствах: Наконец, статическая природа обученных моделей остается ограничением в динамических средах. Будущие исследования должны изучить Адаптация во время тестирования (Test-Time Adaptation, TTA) [42], позволяя модели обновлять статистику пакетной нормализации или легковесные адаптерные слои непосредственно на edge-устройстве. Это позволит дрону или медицинскому устройству "адаптироваться" к новым условиям освещения или профилям сенсорного шума в реальном времени, сохраняя максимальную точность без необходимости полного переобучения на сервере..
7 Заключение
Данное исследование представляет всесторонний анализ архитектуры YOLOv26, которая переопределяет парадигму детектирования объектов в реальном времени за счёт отказа от Non-Maximum Suppression (NMS) в пользу собственной стратегии сквозного обучения. Переход к NMS-Free фреймворку, поддерживаемому новым оптимизатором MuSGD и планировщиком ProgLoss, успешно устраняет исторический компромисс между задержкой и точностью, обеспечивая значительное ускорение на стандартных CPU-устройствах. Кроме того, внедрение Direct Regression head эффективно устраняет "Export Gap", гарантируя детерминированную задержку для ресурсоограниченных edge-устройств. Как показал новый фронт Парето, установленный в официальных бенчмарках, YOLOv26 не только превосходит предыдущие версии и современные аналоги, но и знаменует фундаментальный сдвиг в сторону полностью обучаемых аппаратно-ориентированных конвейеров, критически важных для следующего поколения safety-critical Edge AI приложений..
Благодарность(и)
Автор явно подтверждает использование инструментов искусственного интеллекта исключительно для языковой коррекции и грамматической обработки; все научные концепции, данные и технические инновации, представленные в данной работе, являются оригинальными разработками автора. Все архитектурные интерпретации и математические формулировки представляют собой авторские абстракции, предназначенные для концептуальной ясности, и не отражают официальные спецификации Ultralytics. Официальная документация доступна по адресу: https://docs.ultralytics.com/models/yolo26/.
Ссылки
- [1] (2020) YOLOv4: оптимальная скорость и точность детектирования объектов. Препринт arXiv:2004.10934. Цитируется: §2.2.
- [2] (2017) Soft-NMS – улучшение детекции объектов одной строкой кода. В Труды Международной конференции IEEE по компьютерному зрению (ICCV), Pp. 5561–5569. Внешние ссылки: Document Цитируется в: §3.1.
- [3] (2020) Сквозное обнаружение объектов с использованием Transformers. В Труды Европейской конференции по компьютерному зрению (ECCV)), с. 213–229. Цитируется: §4.6.
- [4] (2025) Можем ли мы доверять ИИ наши уши? Междисциплинарный сравнительный анализ объяснимости в аудиоинтеллекте. IEEE Access 13 (), стр. 179733–179758. Внешние ссылки: Document Цитируется: §6.
- [5] (2025) Развитие обороны и безопасности с использованием методов обнаружения и отслеживания на основе глубокого обучения. В 2025 Международная конференция по интеллектуальным вычислениям и извлечению знаний (ICICKE), Vol. , стр. 1–6. Внешние ссылки: Document Цитируется: §1.2.
- [6] (2025) Беспилотные летательные аппараты в обороне: система военного наблюдения и сопровождения целей на основе компьютерного зрения в реальном времени. В 2025 3-я Международная конференция по интеллектуальным системам, передовым вычислениям и коммуникациям (ISACC)), Vol. , с. 508–513. Внешние ссылки: Document Цитируется: §2.3.
- [7] (2022) К масштабному обнаружению мелких объектов: обзор и тестовые показатели. Препринт arXiv:2207.14096. Цитируется: §3.3.2.
- [8] (2019) Обучение ROI Transformer для детекции ориентированных объектов в аэрофотоснимках. В Труды конференции IEEE/CVF по компьютерному зрению и распознаванию образов (CVPR), стр. 2849–2858. Цитируется: §4.5.
- [9] (2021) TOOD: выравнивание задач в одноэтапном обнаружении объектов. В Труды Международной конференции IEEE/CVF по компьютерному зрению (ICCV)), стр. 3490–3499. Цитируется: §3.3.2.
- [10] (2021) YOLOX: превосходящий серию YOLO в 2021 году. arXiv препринт arXiv:2107.08430. Цитируется: §3.2, §3.2.
- [11] (2021) Обзор методов квантования для эффективного вывода нейронных сетей. arXiv препринт arXiv:2103.13630. Цитируется: §3.2, §5.1.
- [12] (2016) Глубокое остаточное обучение для распознавания изображений. В Труды конференции IEEE по компьютерному зрению и распознаванию образов (CVPR), с. 770–778. Цитируется: §4.3.
- [13] (1986) Метод Ньютона для вычисления матричного квадратного корня. Математика вычислений 46 (174), стр. 537–549. Цитируется: §3.3.1.
- [14] (2019) Подход к обучению с учебным планом для задачи обнаружения объектов. arXiv препринт arXiv:1901.01890. Цитируется: §3.3.3.
- [15] Ultralytics YOLOv8 Внешние ссылки: Link Цитируется: §2.3, §2.3, §3.3.3, §5.1.
- [16] Ultralytics/yolov5: v3.1 — исправления ошибок и улучшения производительности Внешние ссылки: Document, Link Цитируется: §1.2, §2.2.
- [17] (2026) Ultralytics yolov26: нативный сквозной метод обнаружения объектов. Технический отчет Ultralytics. Внешние ссылки: Link Цитируется: §5.2.
- [18] Ultralytics YOLO11 Внешние ссылки: Link Цитируется: 1-й пункт, второй пункт, §1.2, §2.3, §3.2, §3.
- [19] Ultralytics YOLOv6 Внешние ссылки: Link Цитируется: §1.2.1, §2.3, §3.1, §4.1, §4.2, §4.3, §4.5, §4.6, §4.
- [20] (2024) Ортогональные обновления весов для контроля спектральной нормы в глубоком обучении. Технический отчет. Цитируется: §3.3.1.
- [21] (2024) Muon: новый оптимизатор для быстрой сходимости при обучении LLM. Примечание: Пост в блоге GitHub Внешние ссылки: Link Цитируется: §3.3.1.
- [22] (2018) Многозадачное обучение с использованием неопределенности для взвешивания потерь в задачах геометрии сцены и семантики. В Труды конференции IEEE по компьютерному зрению и распознаванию образов (CVPR), с. 7482–7491. Цитируется: 1-й пункт.
- [23] (2019) Увеличение данных для детектирования мелких объектов. Препринт arXiv:1902.07296. Цитируется: §3.3.2.
- [24] (2025) YOLOv13: обнаружение объектов в реальном времени с гиперграфовым усилением адаптивного визуального восприятия. Препринт arXiv:2506.17733. Цитируется: §2.3, §2.3, §5.1.
- [25] (2022) YOLOv6: одноэтапный детектор объектов для промышленных применений. arXiv препринт arXiv:2209.02976. Цитируется: §2.2.
- [26] (2021) Регрессия позы человека с оценкой остаточного логарифмического правдоподобия. В Труды Международной конференции IEEE/CVF по компьютерному зрению (ICCV)), сс. 11039–11048. Цитируется: §4.4.
- [27] (2020) Generalized Focal Loss: обучение качественных и распределённых ограничивающих рамок для плотного обнаружения объектов. Достижения в области нейронных систем обработки информации (NeurIPS) 33, с. 21002–21012. Цитируется: §3.2, §5.1.
- [28] (2013) Сеть в сети. arXiv препринт arXiv:1312.4400. Цитируется: §4.3.
- [29] (2017) Фокус-лосс для плотного обнаружения объектов. В Труды международной конференции IEEE по компьютерному зрению, с. 2980–2988. Цитируется: §3.3.3.
- [30] (2014) Microsoft COCO: Common Objects in Context. В Труды Европейской конференции по компьютерному зрению (ECCV), С. 740–755. Цитируется: §4.4.
- [31] (2025) Muon масштабируем для обучения LLM.. Препринт arXiv:2502.16982. Цитируется: §3.3.1.
- [32] (2017) SGDR: стохастический градиентный спуск с теплыми рестартами. В Международная конференция по представлениям обучения (ICLR), Цитируется: §3.3.3.
- [33] (2017) Унифицированный подход к интерпретации предсказаний моделей. В Достижения в области нейронных систем обработки информации (NeurIPS), с. 4765–4774. Цитируется: §6.
- [34] (2022) RTMDet: эмпирическое исследование проектирования детекторов объектов в реальном времени. Препринт arXiv:2212.07784. Цитируется: второй пункт, §1.2, §3.1, §3.2, §5.2, §5.
- [35] (2021) Обучение переносимым визуальным моделям на основе естественно-языкового обучения. В Международная конференция по машинному обучению (ICML)), стр. 8748–8763. Цитируется: §4.6.
- [36] (2016) Вы смотрите только один раз: унифицированное детектирование объектов в реальном времени. В Труды конференции IEEE по компьютерному зрению и распознаванию образов (CVPR), с. 779–788. Цитируется: §2.1.
- [37] (2017) YOLO9000: лучше, быстрее, мощнее. В Труды конференции IEEE по компьютерному зрению и распознаванию образов (CVPR), с. 7263–7271. Цитируется: §2.1.
- [38] (2018) YOLOv3: инкрементное улучшение. Препринт arXiv:1804.02767. Цитируется: §2.1.
- [39] (2019) Обобщённое пересечение по объединению: метрика и функция потерь для регрессии ограничивающих рамок. В Труды конференции IEEE/CVF по компьютерному зрению и распознаванию образов (CVPR), стр. 658–666. Цитируется: §3.3.2.
- [40] (2017) Grad-CAM: визуальные объяснения из глубоких сетей на основе градиентной локализации. В Труды Международной конференции IEEE по компьютерному зрению (ICCV), с. 618–626. Цитируется: §6.
- [41] (2018) BitFusion: поразрядное конвейерное умножение и накопление для эффективного глубокого обучения. В Труды 45-го ежегодного международного симпозиума по компьютерной архитектуре (ISCA), С. 444–455. Цитируется: §3.2.
- [42] (2020) Тестовая дообучение с самоконтролем для обобщения при сдвигах распределения. В Международная конференция по машинному обучению (ICML), с. 9329–9339. Цитируется: §6.
- [43] (2025) YOLOv12: attention-centric real-time object detection. arXiv препринт arXiv:2502.12588. Примечание: Препринт Цитируется: §2.3.
- [44] (2024) YOLOv10: обнаружение объектов в реальном времени с сквозным обучением. Препринт arXiv:2405.14458. Цитируется в: §2.3, §2.3, §3.1, §5.1.
- [45] (2023) YOLOv7: обучаемый набор "bag-of-freebies" устанавливает новый уровень точности для детекторов объектов в реальном времени. В Труды конференции IEEE/CVF по компьютерному зрению и распознаванию образов (CVPR), стр. 7464–7475. Цитируется: §2.2.
- [46] (2024) YOLOv9: обучение тому, что вы хотите изучать, с помощью программируемой градиентной информации. arXiv препринт arXiv:2402.13616. Цитируется: §2.3.
- [47] (2017) Простое онлайн- и трекинг в реальном времени с глубокой метрикой ассоциации. В Труды Международной конференции IEEE по обработке изображений (ICIP)), с. 3645–3649. Цитируется: §6.
- [48] (2022) PP-YOLOE: эволюционная версия YOLO. arXiv препринт arXiv:2203.16250. Цитируется: §1.2.
- [49] (2022) DAMO-YOLO: отчет о разработке системы детектирования объектов в реальном времени. Препринт arXiv:2211.15444. Цитируется: §1.2.
- [50] (2021) R3Det: уточненный одноэтапный детектор с улучшением признаков для вращающихся объектов. В Труды конференции AAAI по искусственному интеллекту, Vol. 35, с. 3163–3171. Цитируется: §4.5.