Healthcare AI GYM для медицинских агентов
Аннотация
Клиническое рассуждение требует многоэтапных взаимодействий — сбор анамнеза пациента, назначение анализов, интерпретация результатов и принятие безопасных решений о лечении — однако единая обучающая среда, обеспечивающая охват клинических областей и специализированные инструменты для обучения обобщаемых медицинских ИИ-агентов с помощью reinforcement learning, остается недостижимой. Мы представляем всестороннее эмпирическое исследование многошагового агентного RL для медицинского ИИ, построенное на Healthcare AI GYM (среда для специализированного обучения), совместимая со средой gymnasium система, охватывающая 10 клинических областей с более чем 3,6 тыс. задач, 135 специализированных инструмента и базой знаний из 828 тыс. медицинских текстов. Наш анализ показывает, что агентная многоходовая структура деградирует в многословные одноходовые монологи, характеризующиеся монотонным взрывным ростом длины и одновременным снижением частоты использования инструментов. Мы демонстрируем, что этот коллапс, наряду с нестабильностью дистилляции, обусловлен несоответствием разреженных терминальных вознаграждений последовательным клиническим траекториям. Установлено, что стандартный GRPO демонстрирует высокую итоговую точность на некоторых бенчмарках, но страдает от нестабильности обучения, что проявляется в значительных колебаниях длины ответов и затяжных периодах сходимости. Для повышения эффективности и стабильности обучения мы предлагаем Turn-level Truncated On-Policy Distillation (TT-OPD) — фреймворк самодистилляции, в котором градиентно-независимый EMA-учитель использует информацию с привилегированным доступом к результатам для обеспечения плотной KL-регуляризации, учитывающей исход, на каждом шаге диалога. TT-OPD показывает наилучшие результаты на 10 из 18 бенчмарков со средним улучшением на +3,9 п.п. относительно базового не-RL подхода, обеспечивая более быструю раннюю сходимость, контролируемую длину ответов и устойчивое многоходовое использование инструментов. Дополнительный анализ выявляет фундаментальный разрыв между агентными и текстовыми трансферами: RL улучшает процедурную компетентность, но не переносится на текстовые QA-бенчмарки из-за размывания вознаграждений, связанных с форматом. Среда, обучающий конвейер и все экспериментальные артефакты находятся в открытом доступе..
1 Введение
Последние достижения в области медицинских LLM сместили границу от статического извлечения знаний к сложному клиническому анализу. (Nori et al., 2023; Singhal et al., 2023; Chen et al., 2024). В то время как передовые модели все чаще демонстрируют успехи в сдаче медицинских экзаменов, их производительность по-прежнему в основном ограничена пассивными, одноэтапными тестами. (Jin et al., 2021; Hendrycks et al., 2021; Pal et al., 2022). Однако подлинная клиническая практика по своей природе агентна и многоэтапна: она требует итеративного цикла сбора анамнеза, выбора диагностических инструментов и корректировки планов лечения на основе изменяющегося клинического контекста. (Thirunavukarasu et al., 2023; Yao et al., 2023). Несмотря на появление моделей, оптимизированных для логического вывода, (Wei et al., 2022; Wang et al., 2023), сохраняется критический «разрыв в действиях» — современные подходы эффективно формализуют медицинскую логику, но демонстрируют трудности в поддержании стабильных траекторий, усиленных инструментами, в открытых клинических средах (Shen et al., 2026; Schick et al., 2023). Преодоление этого разрыва требует перехода от вопросно-ответных систем к агентному обучению с подкреплением, где модели учатся ориентироваться в условиях высокой неопределенности при принятии многошаговых медицинских решений. (Schulman et al., 2017; Shao et al., 2024; Ouyang et al., 2022).
Существующие среды для медицинских агентов охватывают лишь фрагменты задачи клинического рассуждения. AgentClinic (Schmidgall et al., 2025) симулирует диагностические диалоги, но не обладает интеграцией использования инструментов и RL-обучающей структурой. Agent Hospital (Li et al., 2024) фокусируется на многозадачных рабочих процессах с участием нескольких агентов, а не на явной оптимизации политик через RL. В то время как MedAgentGym (Xu et al., 2026) предлагает интерфейс Gymnasium, его система инструментов в основном ориентирована на код (например, песочницы Python), а не на клиническую практику (например, заказ анализов, оценку тяжести состояния), что ограничивает его экологическую валидность. Кроме того, MedOpenClaw (Shen et al., 2026) выявляет «парадокс использования инструментов», когда прямое промптирование с профессиональными инструментами снижает производительность, подчеркивая, что компетентность в инструментально-опосредованном рассуждении должна осваиваться через Reinforcement Learning (RL), а не просто промптироваться. Хотя такие фреймворки, как ReAct (Yao et al., 2023) предоставлять шаблоны логических рассуждений, ни одна из существующих сред не предлагает одновременно: (1) широкое мультидоменное клиническое покрытие, (2) аутентичную экосистему инструментов, (3) оценку критически важных аспектов безопасности и (4) бесшовную совместимость с современными RL-фреймворками. Это мотивирует Healthcare AI GYM, единая среда, отвечающая этим требованиям.
Ghb обучении агентов в Healthcare AI GYM При многократном применении RL выявляются три взаимосвязанные патологии, отсутствующие в однократных сценариях: (1) Взрыв ответов: Выходные данные монотонно возрастают к пределу. При отсутствии промежуточной обратной связи (Lightman et al., 2024; Uesato et al., 2022), модель использует покрытие на уровне токенов в качестве суррогата завершения задачи, раздувая ответы, чтобы «захватить» правильный ответ в море бессвязности; (2) Многократный коллапс: Агентная структура деградирует от скоординированных диалогов с использованием инструментов до многословных монологов в один ход. Этот коллапс указывает на то, что модель воспринимает многословность в один ход как путь оптимизации с меньшими энергетическими затратами по сравнению со сложной политикой очередности ходов, необходимой для последовательного рассуждения. (Shi et al., 2024; Jung et al., 2025). Критически важно, что эти две патологии причинно связаны: по мере того, как модель смещается в сторону одноходовых монологов, ответы становятся длиннее, чтобы компенсировать отказ от вызовов инструментов, а результирующий взрыв длины ещё больше препятствует многоходовому взаимодействию — создавая самоподдерживающийся цикл коллапса; (3) Нестабильность дистилляции: On-policy distillation (OPD), хотя эффективен для одношагового рассуждения (Zhao et al., 2026; Yang et al., 2026), проваливается в агентных сценариях. Комбинаторная сложность пространства траекторий приводит к тому, что политики учителя устаревают значительно быстрее, чем в ограниченных задачах вопросно-ответных систем. (Song and Zheng, 2026). Эти неудачи имеют общую причину: структурное несоответствие между редкими терминальными вознаграждениями и последовательным характером агентных траекторий. Стандартный GRPO (Shao et al., 2024) присваивает единообразную оценку преимущества всем токенам в многошаговой последовательности, не учитывая вклад отдельных шагов и приводя к нестабильной сходимости.
В данной статье представлено всестороннее эмпирическое исследование многошагового агентного обучения с подкреплением (RL) для медицинского ИИ. Мы провели оценку на 18 тестовых наборах данных, включающих MC QA, визуальный QA, анализ EHR и длинные формы QA, демонстрируя, что TT-OPD достигает наилучших результатов на 10 из 18 тестов со средним улучшением на +3,9 п.п. по сравнению с базовым подходом без RL, включая MedQA 87,1% (+16,4 п.п. относительно базового уровня), MedMCQA 66,2% и MIMIC-III 62,7%. Vanilla GRPO демонстрирует высокую обучение точность (+9,4 п.п.), но страдает от описанной выше нестабильности обучения. Для повышения эффективности и стабильности обучения мы предлагаем Turn-Level Truncated On-Policy Distillation (TT-OPD) — фреймворк самообучения, стабилизирующий процесс обучения за счет: (1) учителя на основе экспоненциального скользящего среднего (EMA) без градиентов (Tarvainen & Valpola, 2017), (2) условные по результату привилегированные подсказки, обеспечивающие плотную KL-регуляризацию на уровне хода, и (3) формирование вознаграждения с контролем длины (Yeo et al., 2025). Наши вклады:
Наши вклады заключаются в следующем:. Healthcare AI GYM, совместимая со средой Gymnasium система, охватывающая 10 клинических областей с более чем 3,6 тыс. задач, 135 специализированными инструментами, базой знаний из 828 тыс. медицинских текстов и учитывающей безопасность 5-мерной функцией вознаграждения (Приложение A). Наша новизна заключается в регуляризации с учетом результата: путем внедрения сигналов корректности в контекст учителя (но не ученика), градиент KL обеспечивает плотное пошаговое руководство, поддерживая частоту использования инструментов (7,0–7,4 шагов) и контролируемую длину ответов (5,7–9,3K токенов). Четыре варианта абляции отслеживают прогрессию сбоев от коллапса KL (периодический сброс) до взрывного роста ответов (без контроля длины), идентифицируя коллапс в многошаговом режиме как агент-специфичный режим отказа, отсутствующий в однократном OPD (Yang et al., 2026; Zhao et al., 2026).
2 Связанные работы
Медицинские ИИ-агенты
Современные медицинские агентные среды охватывают лишь отдельные аспекты клинического мышления. AgentClinic (Schmidgall et al., 2025) симулирует диагностические диалоги, но не использует инструменты и обучение с подкреплением (RL); Agent Hospital (Li et al., 2024) моделирует многозадачные рабочие процессы без оптимизации политик; MedAgentGym (Xu et al., 2026) предоставляет интерфейс Gymnasium с инструментами, ориентированными на код, а не клинические обоснования; и MedOpenClaw (Shen et al., 2026) показывает, что наивное добавление профессиональных инструментов ухудшает производительность без обучения с подкреплением (RL). В части рассуждений MediX-R1 (Mullappilly et al., 2026) применяет GRPO для медицинских рассуждений, но ограничен генерацией в один шаг, а также HuatuoGPT-o1 (Chen et al., 2024) исследует сложное медицинское обоснование без многошагового использования инструментов. Дополненные инструментами LLM (Schick et al., 2023; Qin et al., 2024) обученные вызывать внешние API и генерацию с расширением выборки (Lewis et al., 2020) из медицинских баз знаний повышает фактическую обоснованность (Jin et al., 2023). Хотя эти работы продвигают извлечение медицинских знаний в рамках единичного взаимодействия, ни одна из них не затрагивает проблему поведенческого коллапса, возникающего в долгосрочных клинических траекториях. Наше исследование заполняет этот пробел, предлагая унифицированную среду обучения для нескольких доменов, включающую клиническую экосистему из 135 инструментов и 5-ти мерную функцию вознаграждения, специально разработанную для стабилизации обучения стратегии агентов..
RL для LLM и дистилляция на основе текущей политики
Методы градиента политики (стратегии выбора следующего токена) (Schulman et al., 2017) лежат в основе современных методов согласования LLM (Ouyang et al., 2022), с альтернативами, такими как DPO (Rafailov et al., 2023) обход моделей вознаграждения. GRPO (Shao et al., 2024) использует групповые относительные вознаграждения; DAPO (Yu et al., 2025) вводит динамический сэмплинг и асимметричное клиппирование; Dr. GRPO (Liu et al., 2025) устраняет смещение из-за нормализации длины. Однако в онлайн-версии GRPO с одной итерацией коэффициент важности , так DAPO’s clipping и GSPO’s (Zheng et al., 2025) importance sampling (метод важностнойвыборка), разработанного для многоитерационного обучения, не оказывают эффекта. Дистилляция знаний (knowledge distillation) (Hinton et al., 2015) был расширен для on-policy окружений: OPSD (Zhao et al., 2026) вводит метод обучения с привилегированным учителем; Self-Distilled RLVR (Yang et al., 2026) разделяет направление и величину обновления; SRPO (Li et al., 2026) унифицирует групповую относительность и самодистилляцию; CRISP (Sang et al., 2026) применяет OPD для сжатия рассуждений. Song and Zheng (2026) идентифицируют агент-уровеня OPD как открытую проблему. HiLL (Xia et al., 2026) совместно обучает адаптивную политику подсказок, в то время как Complementary RL (Muhtar et al., 2026) совместно развивает экстрактор опыта. Однако существующие методы OPD в основном стабилизируют одношаговые рассуждения и недостаточно исследуются при применении к высокоразмерному комбинаторному пространству траекторий использования медицинских инструментов. TT-OPD решает эту проблему, вводя учителя EMA, обусловленного результатом, который обеспечивает плотную регуляризацию на уровне шагов, предотвращая коллапс KL и взрыв длины, присущие классическому on-policy агентному RL..
Оптимизация многошаговых агентов
Расширение RL за пределы однократного взаимодействия требует распределения заслуг между шагами. Модели вознаграждения процесса. (Lightman et al., 2024; Uesato et al., 2022) обеспечивают пошаговую обратную связь для рассуждений, но предполагают линейные цепочки. Self-RAG (Asai et al., 2023) обучает модели адаптивно извлекать информацию и саморефлексировать; Self-BioRAG (Jeong et al., 2024) расширяет это на биомедицинскую область, комбинируя генерацию с усилением выборки и саморефлексию для улучшения медицинских рассуждений; и STaR (Zelikman et al., 2022) бутстрапинг рассуждений через самообучаемые рациональные основы — все это имеет отношение к нашему подходу, обусловленному результатом, но ограничено одношаговыми сценариями. Для многошаговых агентов, использующих инструменты, DMPO (Shi et al., 2024) выводит вариант DPO с ограничениями на заполнение состояний и действий; DiaTool-DPO (Jung et al., 2025) Моделируют диалоги с инструментальным усилением как марковские процессы принятия решений (MDP) с 5 состояниями; Agent-R (Yuan et al., 2025) использует MCTS для коррекции траектории; SPORT (Li et al., 2025) применяет пошаговую настройку предпочтений для мультимодального использования инструментов; PGPO (Cao et al., 2025) направляет агентов с помощью планов в стиле псевдокода; и DEPO (Chen et al., 2025) совместно оптимизирует эффективность на каждом шаге и всей траектории. В отличие от методов оптимизации предпочтений на фиксированных наборах данных, TT-OPD обеспечивает онлайн плотную регуляризацию через трекинг учителя с экспоненциальным скользящим средним (EMA), обусловленным выходными данными, — решение уникальных проблем нестабильности при обучении с политикой на множестве ходов, в частности, коллапса в многословные монологи. Характеризуя разрыв переноса между агентным и текстовым поведением, мы представляем первый систематический анализ того, как многошаговая агентная компетентность расходится со стандартным текстовым рассуждением в процессе обучения с подкреплением. 111Наш конвейер обучения построен на verl (Sheng et al., 2024), который обеспечивает эффективную многоходовую GRPO на основе FSDP с поддержкой гибридного движка..
3 Healthcare AI GYM: Проектирование среды
Healthcare AI GYM является стандартизированной высокоточной средой обучения с подкреплением, предназначенной для преодоления разрыва между статическим извлечением медицинских знаний и агентным клиническим исполнением. Разработаная на основе Gymnasium (Towers et al., 2024) интерфейсе, она предоставляет унифицированный API—включая шаг(действие)/рендер()—для обеспечения беспрепятственной интеграции с современными конвейерами обучения с подкреплением. Как показано на Рисунке 1, Наша среда выходит за рамки простого ответа на вопросы, охватывая 10 различных клинических областей — от управления электронными медицинскими картами (EHR) (Johnson et al., 2016) пересекать диагностические пути в различных областях — каждый из которых требует специализированного использования инструментов и принятия решений с учетом безопасности.
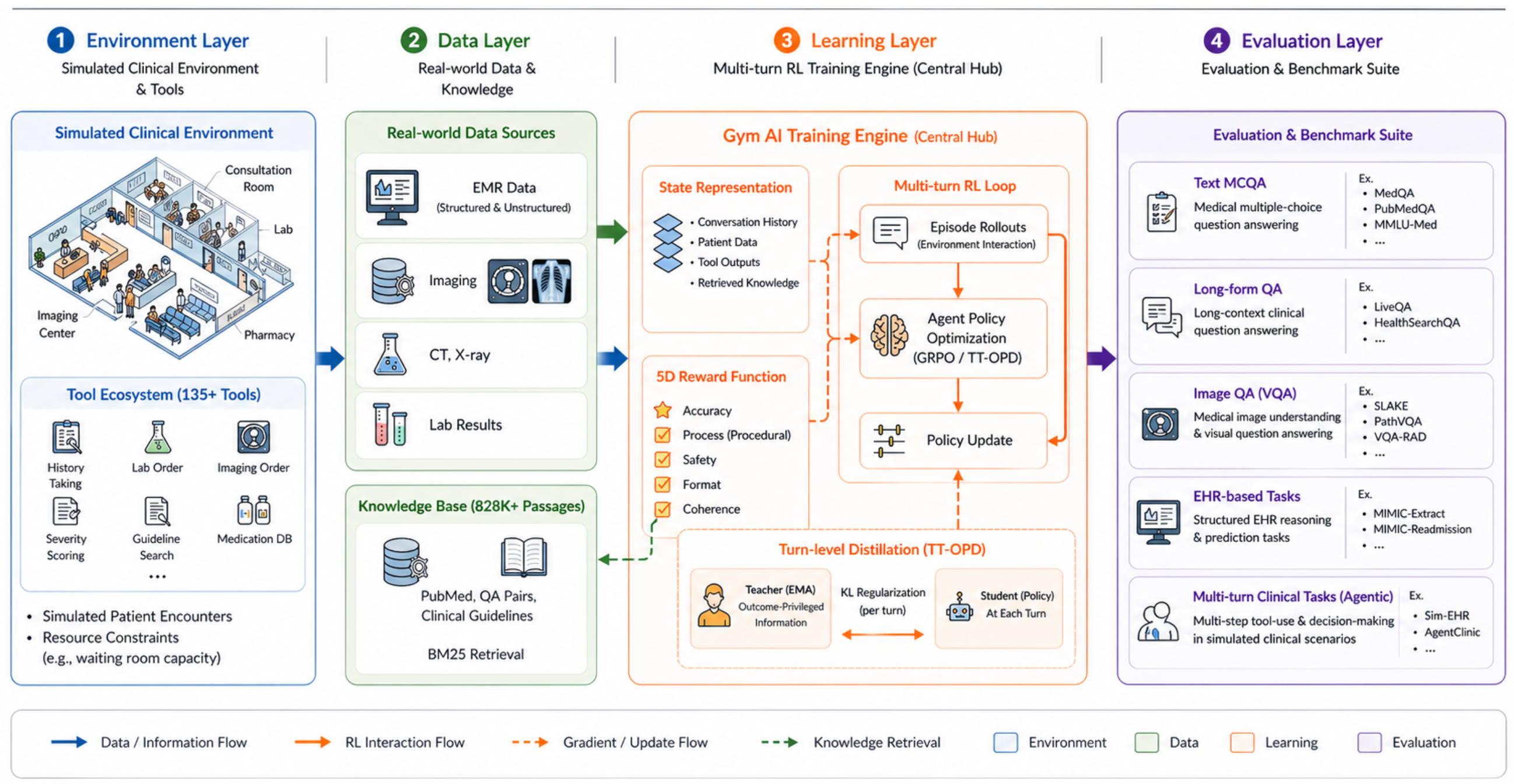
Вместо использования универсальных шаблонов применения инструментов, Healthcare AI GYM вводит клинически обоснованный набор инструментов. Мы предоставляем 135 специализированных инструментов (объединенных в 25 категорий для пользователей), классифицированных по: (1) поиску доказательств (BM25-based KB querying), (2) клинической оценке (22 валидированных оценочных инструмента), (3) вмешательствам и (4) структурам рассуждений. Используя шаблон автоматической генерации на основе декораторов для OpenAI-совместимых определений, мы обеспечиваем расширяемость среды при сохранении высокой экологической валидности, необходимой для аутентичного клинического моделирования. Полный набор инструментов представлен в Приложении. C.
Для передачи нюансов клинической компетентности мы выходим за рамки бинарной точности.. Healthcare AI GYM реализует 5D Reward Function, которая формализует клинические приоритеты в единую цель оптимизации: . Наша схема весовых коэффициентов по умолчанию (, плюс необязательное измерение утверждения Когда доступны аннотации рубрик, это гарантирует, что диагностическая точность и безопасность процедур являются основными факторами обновления политик. Важно отметить, что наша структура включает таксономию тяжести по безопасности и проверки логической согласованности, решая проблему "размытия вознаграждения за формат", когда агенты отдают приоритет структурной корректности над клинической полезностью (см. Предложение E.2).
4 Дистилляция с усечением на уровне отдельных действий
4.1 Предварительные сведения
Мы формализуем процесс принятия решений клинического агента как частично наблюдаемый марковский процесс принятия решений (POMDP). На каждом шаге , агент получает наблюдение —включающий историю бесед, результаты клинических инструментов и данные пациента — и генерирует действие , где включает как естественное языковое рассуждение, так и структурированные вызовы инструментов. Среда выполняет , переход состояния в . Эпизод завершается при успешном submit_answer() вызове или достижение горизонта . Полная траектория оценивается разреженной терминальной наградой вычисляется только в конце эпизода.
Разреженные терминальные вознаграждения в многошаговых сценариях создают серьёзную проблему распределения заслуг. В то время как модели пошаговых вознаграждений (PRMs...) (Lightman et al., 2024) предоставляют пошаговую обратную связь в линейных цепочках рассуждений, их сложно адаптировать к агентным средам по следующим причинам: (1) Сложность действий — пошаговая аннотация структурированных вызовов инструментов JSON — задача нетривиальная; и (2) Динамический контекст — пространство наблюдений непредсказуемо меняется после выполнения инструмента, что делает качество шага рассуждения зависимым от полученных внешних данных. Наша 5D-награда смягчает эту проблему за счет учета процедурного качества, но остается принципиально эпизодической, что требует более плотного сигнала регуляризации во время обучения.
Мы используем GRPO (Shao et al., 2024), который расширяет PPO, заменяя обученную функцию ценности на групповые относительные преимущества. Для батча количество развёрток на промпт, усечённая суррогатная функция цели:
| (1) |
где является групповым относительным преимуществом. В нашей онлайн-настройке с одной итерацией, где , коэффициент важности тождественно равен 1.0, что делает механизмы многоитерационного ограничения неэффективными.
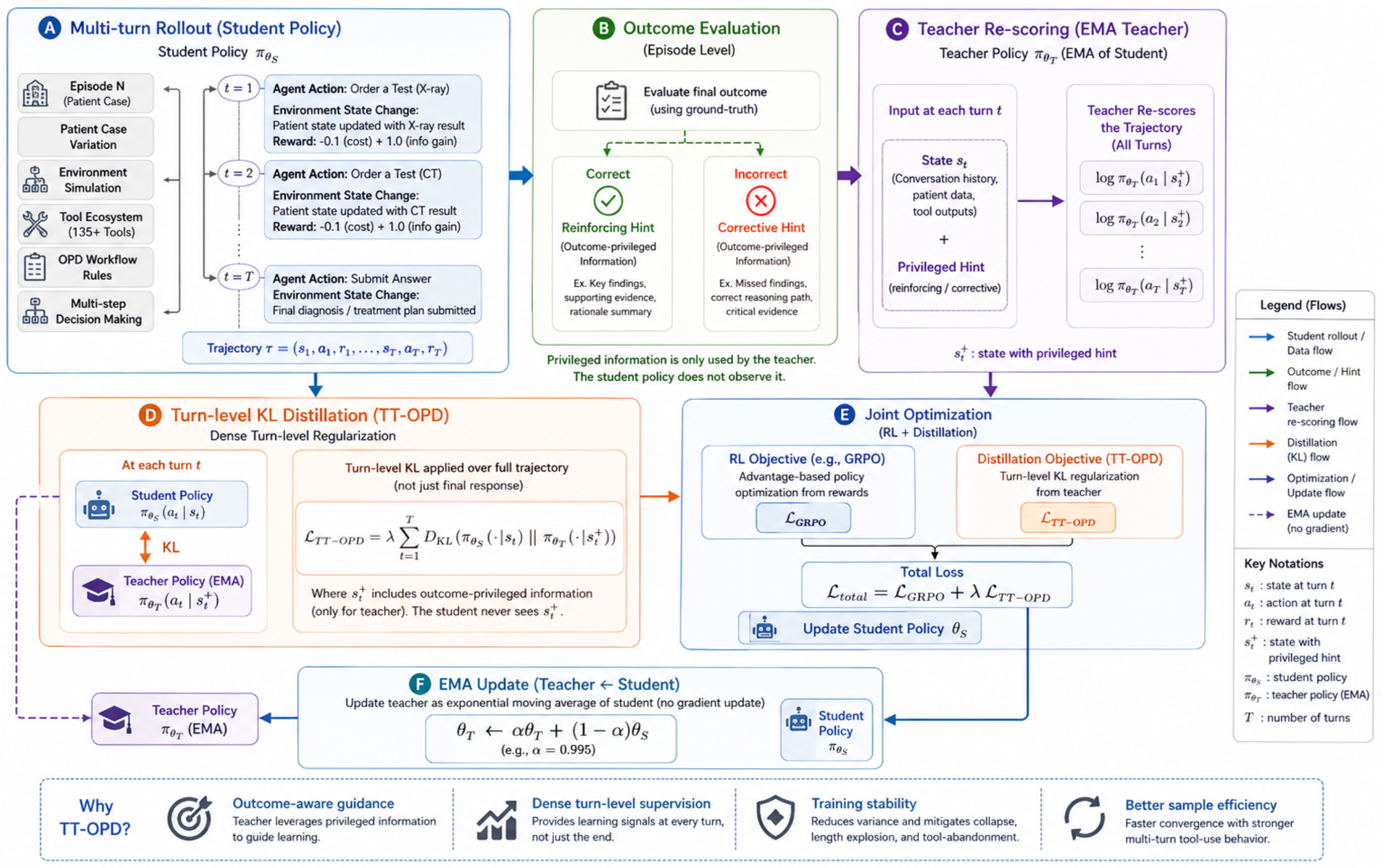
4.2 Метод TT-OPD
Учитывая описанные режимы отказа в §1, нам необходимы как надежный сигнал обучения для обеспечения точности, так и структурная регуляризация для поддержания поведения в многоходовом взаимодействии. TT-OPD решает эти задачи, используя модель-учитель, которая отслеживает модель-ученика через обновления с экспоненциальным скользящим средним (EMA), обеспечивая стабильность без явных градиентных обновлений для учителя..
Основная цель регулирует политику ученика в сторону учителя на всех этапах диалога.:
| (2) |
где обозначает состояние, дополненное результат-привилегированная информация. Термин «turn-level» подразумевает вычисление расхождения KL по всей траектории, а не только по финальному ответу, тогда как «truncated» означает отбрасывание вкладов от любых шагов, превышающих лимит контекста. .
Привилегированные подсказки, зависящие от результата
Ключевым конструктивным решением является использование привилегированных подсказок, зависящих от результата. Учитель получает сигналы, зависящие от правильности для каждой траектории:
-
•
Усиление подсказок (напр.., “Рассуждения представляются обоснованными”) для корректных траекторий повышают уверенность учителя в успешных путях рассуждений.
-
•
Корректирующие подсказки (например., “Пересмотрите дифференциальный диагноз”) смещают распределение внимания учителя в сторону от выявленных закономерностей в ошибках.
Ключевым моментом является то, что эти привилегированные токены вставляются на границе между промптом и ответом, но но удаляются из выходных логарифмических вероятностей учителя. Следовательно, обучаемый никогда явно не наблюдает подсказки; вместо этого подсказки модулируют распределение учителя, обеспечивая регуляризацию KL с учетом результата на каждом шаге. Это превращает TT-OPD в регуляризатор на уровне траектории, который стабилизирует корректные поведения, одновременно активно наказывая процедурные ошибки через градиент KL..
Механизмы стабильности
Мы применяем два основных метода для обеспечения стабильности обучения. Во-первых, модель-учитель (teacher) обновляется исключительно через EMA (Tarvainen & Valpola, 2017): с . Обновление происходит каждые 5 шагов для плавного включения изученных весов. Периодический применяется резервная копия с жёсткой настройкой ( каждые 30 шагов) применяется поверх непрерывного EMA для предотвращения чрезмерного расхождения между учителем и учеником, гарантируя сохранение информативности сигнала KL на протяжении всего обучения..
Чтобы предотвратить экспоненциальный рост длины ответа, мы используем функцию вознаграждения с ограничением по длине (Yeo et al., 2025):
| (3) |
где . Такое формирование препятствует монотонному увеличению длины по мере приближения ответов . Финальная комбинированная функция потерь определяется как:
| (4) |
где обеспечивает сильную регуляризацию против коллапса агентности.
5 Эксперименты
5.1 Настройка
Ванильный базовый уровень GRPO и все эксперименты OPD (четыре варианта абляции плюс полный метод) используют Qwen3.5-9B. (Qwen Team, 2025), обученная с нуля без предварительной подготовки методом SFT, чтобы изолировать влияние каждого компонента без искажений от предшествующей тонкой настройки. Базовый вариант GRPO использует идентичные гиперпараметры (Таблица 4) но без дистилляции или косинусного вознаграждения, что служит прямым сравнением для эффективности и стабильности обучения. Мы не проводим сравнений между треками; результаты каждого трека самодостаточны. Все эксперименты выполняются на 8A100 80GB с нулевым загрязнением данных, подтверждённым с помощью fingerprinting тестового набора. (Yang et al., 2023). Все гиперпараметры обучения (скорость обучения, размер пакета, затухание EMA, температура и т. д.) указаны в Приложении F. Точность валидации TT-OPD вычисляется на отложенной выборке из 307 задач (149 медицинских вопросов-ответов, 37 визуальных диагнозов, 25 клинических диагнозов, 25 взаимодействий лекарств, 25 электронных медицинских карт, 20 триажей, 20 психиатрических случаев, 6 акушерских случаев), отобранных без возвращения из того же распределения домена, что и обучающие данные. Оценка проводится по 18 тестам, охватывающим текстовые вопросы-ответы, визуальные вопросы-ответы, развернутые вопросы-ответы и рассуждения на основе электронных медицинских карт (Приложение G).
5.2 Бенчмарк-оценка
Сначала мы представляем основные результаты. Ключевое методологическое наблюдение лежит в основе нашего протокола оценки.: одношаговая генерация демонстрирует нулевую точность на всех тестовых наборах данных поскольку модель, обученная по методу TT-OPD, научилась рассуждать с помощью вызовов инструментов (search оценивать submit), а при оценке в режиме single-turn этот конвейер обрывается до submit_answer достигается. Поэтому мы проводим оценку с использованием того же многошагового AgentRunner и инструментов предметной области, что и во время обучения — это не артефакт, а особенность парадигмы агентного обучения. Таблица 1 представляет результаты по 18 тестовым наборам, сгруппированным в четыре категории.
| Без RL | С помощью RL | ||||
| Категория | Бенчмарк | База (текст) | Base+AR | GRPO | TT-OPD |
| Базовый модуль: Qwen3.5-9B | |||||
| MC QA | MedQA (USMLE) | 70.7 | 78.8 | 85.5 | 87.1 |
| MMLU-Med. (6 подразделов).) | 83.8 | 60.6 | 60.1 | 65.5 | |
| MedMCQA | 63.8 | 55.8 | 58.0 | 66.2 | |
| Визуальный вопросно-ответный анализ (Visual QA) | VQA-RAD | 52.5 | 63.2 | 60.7 | 63.1 |
| PathVQA | 40.5 | 38.7 | 41.5 | 45.3 | |
| SLAKE | 79.0† | 30.6 | 29.5 | 32.1 | |
| PMC-VQA | 57.9† | 35.1 | 34.2 | 38.9 | |
| VQA-Med-2021 | 8.6 | 9.8 | 10.7 | 15.2 | |
| Quilt-VQA | 25.2 | 27.8 | 25.2 | 30.7 | |
| Электронная медицинская карта (EHR) | MIMIC-III | 58.5 | 62.1 | 61.1 | 62.7 |
| eICU | 53.2 | 55.9 | 55.5 | 57.1 | |
| LFQA | LiveQA | 53.2 | 58.2 | 57.7 | 62.5 |
| MedicationQA | 49.5 | 53.1 | 55.8 | 60.9 | |
| HealthSearchQA | 39.8 | 41.9 | 39.5 | 45.3 | |
| KQA-Golden | 55.7 | 62.1 | 65.3 | 64.1 | |
| KQA-Silver | 52.5 | 61.7 | 64.9 | 62.8 | |
Множественный выбор в вопросах и ответах (QA).
TT-OPD демонстрирует наилучшие результаты на MedQA (87,1%) и MedMCQA (66,2%), превосходя как базовую модель, так и GRPO. GRPO показывает сопоставимые результаты на MedQA (85,5%), но уступает на MedMCQA (58,0%). На MMLU-Med (6 подтипов) оценка базовой модели по логарифмической вероятности достигает 83,8%, однако многошаговая агентная оценка снижает результат до 60,6% (Base+AR) и 65,5% (TT-OPD) — это устойчивое накладные расходы на агентную оценку где многократные вызовы инструментов приводят к ошибкам в задачах на воспроизведение знаний. Примечательно, что TT-OPD демонстрирует улучшение на +4,9 п.п. по сравнению с Base+AR на MMLU, что указывает на частичную компенсацию этих затрат с помощью RL..
Визуальный вопросно-ответный анализ (Visual QA).
На 6 тестах VQA модель TT-OPD демонстрирует наилучшие или близкие к наилучшим результаты в 5 случаях (PathVQA 45.3%, SLAKE 32.1%, PMC-VQA 38.9%, VQA-Med-2021 15.2%, Quilt-VQA 30.7%), тогда как Base+AR лидирует на VQA-RAD (63.2%). Для SLAKE и PMC-VQA наблюдается значительный разрыв между текстовой оценкой (79.0%, 57.9%†) и многократное агентное оценивание (30,6%, 35,1%), что согласуется с наблюдаемым паттерном агентных накладных расходов в Multi-choice QA.
Электронные медицинские записи (EHR) и вопросы с развернутыми ответами (Long-Form QA).
Анализ медицинских записей (EHR) демонстрирует устойчивое преимущество TT-OPD (MIMIC-III 62,7%, eICU 57,1%) по сравнению с Base+AR и GRPO, оцененное через scoring на основе действий (ожидаемое покрытие вызовов инструментов). Длинные вопросы и ответы (LFQA) выявляют более сложную картину: TT-OPD лидирует в 3 из 5 тестов (LiveQA 62,5%, MedicationQA 60,9%, HealthSearchQA 45,3%), тогда как GRPO показывает лучшие результаты в задачах, требующих глубоких знаний (KQA-Golden 65,3%, KQA-Silver 64,9%). Это указывает на то, что более высокая пиковая точность обучения GRPO обеспечивает лучшее воспроизведение фактов в открытых сценариях, в то время как TT-OPD превосходит в структурированном клиническом анализе..
Ключевые выводы. (1) TT-OPD демонстрирует наилучшие результаты на 12 из 18 бенчмарков, подтверждая широкую компетентность в областях MC QA, VQA, EHR и LFQA. (2) Многозадачная агентная оценка вносит систематические накладные расходы в бенчмарках на воспроизведение знаний (MMLU: 83.8% text 60,6% Base+AR), что подтверждает компромисс между параметрической точностью и поисково-усиленными рассуждениями при агентной оценке. (3) GRPO демонстрирует высокую эффективность в задачах, требующих интенсивного использования знаний (KQA-Golden/Silver), но уступает TT-OPD в процедурных задачах (EHR, MedMCQA, большинство VQA). Подробный анализ по каждому бенчмарку приведен в Приложении. D.
5.3 TT-OPD Training Dynamics
Установив, что TT-OPD демонстрирует конкурентоспособные результаты в бенчмарках благодаря многократной оценке, мы переходим к анализу как эта производительность проявляется в процессе обучения. На шаге 60 TT-OPD достигает 61.1% точность валидации (+8.5 п.п. по сравнению с базовой моделью в 52.6%), со средней точностью 59.5% (1.4 п.п.) на шагах 40–60. Базовый алгоритм GRPO без дообучения и косинусного вознаграждения достигает более высокого пика в 62.0% на шаге 55, но с длинами ответов, колеблющимися в диапазоне 7.7K–10.8K токенов на протяжении всего обучения. Рисунок 3 показывает полные траектории обучения, выявляя три ключевые динамики и компромисс между эффективностью и стабильностью для GRPO и TT-OPD:
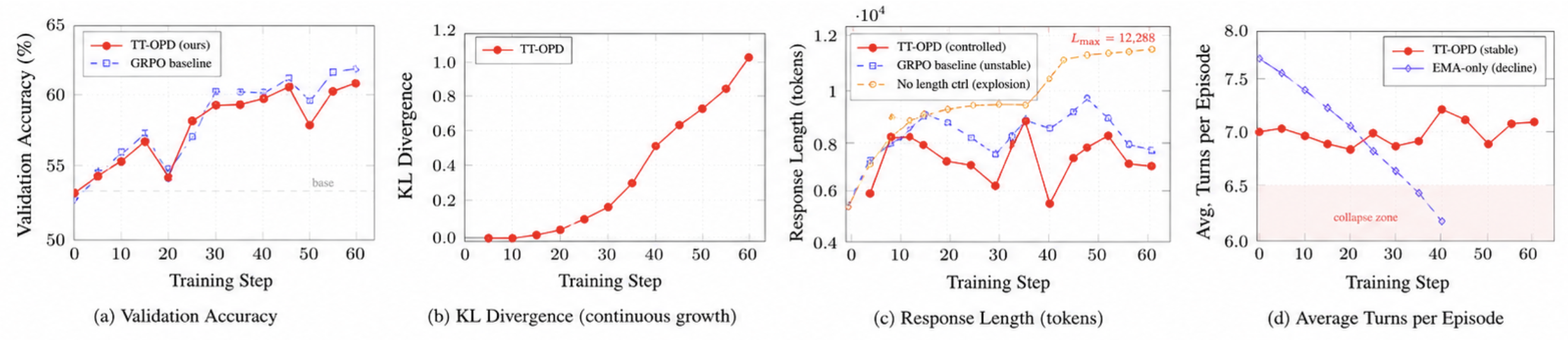
(1) Немонотонная сходимость (Рисунок 3a): как TT-OPD, так и GRPO демонстрируют пилообразные паттерны с возрастающими пиками. GRPO достигает несколько более высокого пика (62.0% на шаге 55 против 61.1% у TT-OPD на шаге 60), но ценой нестабильности длины ответа (колебания в диапазоне 7.7K–10.8K токенов), которую контролирует косинусная награда TT-OPD. Ключевое преимущество TT-OPD заключается не в абсолютной точности, а устойчивость обучения: контролируемая длина ответа и устойчивое использование инструментов в многошаговом режиме на протяжении всего обучения. (2) Контроль длины ответа (Рисунок 3с): TT-OPD с косинусной функцией вознаграждения удерживает длину ответов в диапазоне 5,7–9,3 тыс. токенов, в отличие от монотонного роста до 12 тыс. токенов при отсутствии контроля длины. (3) Устойчивая многовитковая структура (Рисунок 3d): среднее количество ходов остается стабильным на уровне 7.0–7.4 на протяжении всего обучения, что подтверждает сохранение многократного использования инструментов, а не их схлопывание в однократные монологи. Мы также приводим наши аналитические выводы в Приложении. E.
6 Анализ
6.1 Прогрессирование отказов OPD
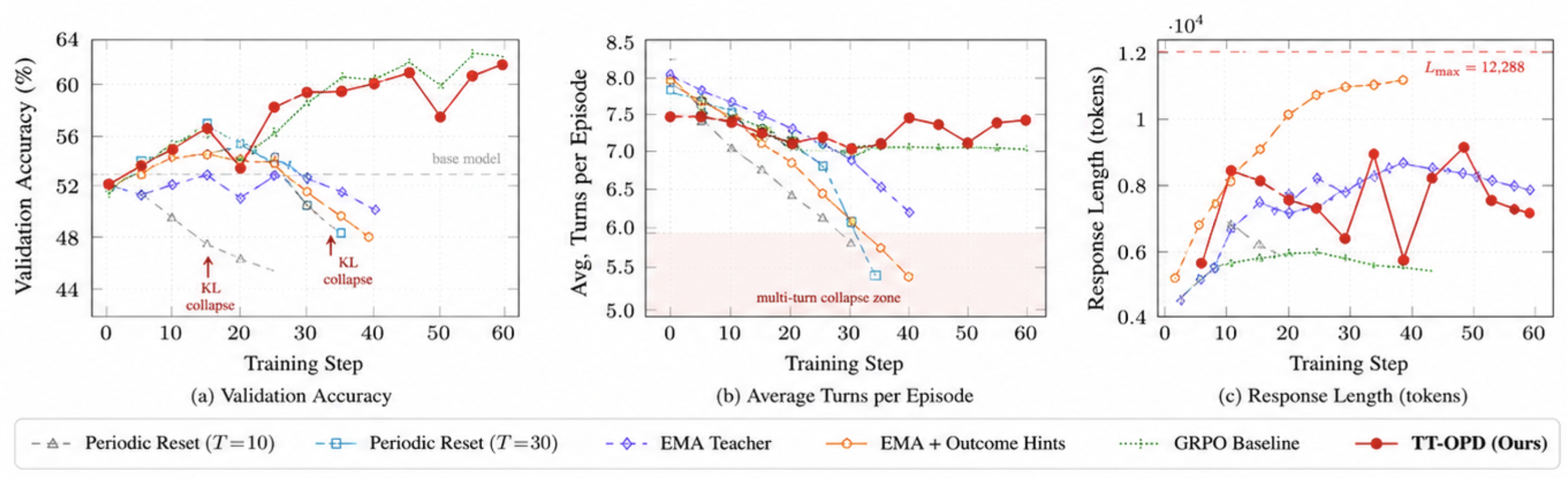
Наше исследование четырех вариантов OPD выявляет прогрессию режимов отказа (Рисунка 4), расширение паттернов нестабильности Yang et al. (2026) и Zhao et al. (2026) в многозадачную агентную среду. Каждый вариант добавляет один компонент, изолируя его влияние.
(1) Периодический сброс учителя (серые/голубые кривые на Рисунке 4). Учитель периодически заменяется весами ученика ( каждый шаги). Это приводит к катастрофическому коллапсу KL-дивергенции: при каждом событии копирования KL-дивергенция резко падает от накопленного значения до почти нуля (например,., на шаге 10 с ), разрушая градиент дистилляции, который направлял студента. В результате наблюдается монотонное снижение точности. (, панель а), поскольку у студента нет стабильного эталонного распределения. Одновременно использование инструментов в многошаговом режиме снижается с 7,65 до 5,52 шагов за эпизод (панель b) — агент обучается тому, что монологи в один шаг оптимизировать проще, чем согласованные последовательности применения инструментов..
(2) EMA teacher (без кондиционирования). Замена периодических сбросов на экспоненциальное скользящее среднее () полностью устраняет коллапс KL. Теперь учитель плавно следует за учеником, а KL непрерывно растет вместо характерных пилообразных падений. Это приводит к немонотонной сходимости: точность достигает на шаге 40 наблюдается улучшение на +1,2 п.п. Однако без кондиционирования, учитывающего результат, распределение учителя обеспечивает лишь обобщенный регуляризационный сигнал, и повороты по-прежнему разрушаются. () поскольку целевое значение KL не кодирует что что составляет хорошее поведение в многоходовом взаимодействии.
(3) EMA + подсказки по результату (без контроля длины) (оранжевые кривые). Добавление привилегированных подсказок, зависящих от исхода, создает начальное плато точности на (шаги 10–20, панель а), поскольку условное распределение учителя теперь обеспечивает ориентацию с учетом результата. Однако подсказки непреднамеренно поощрять взрыв ответов: положительные подсказки усиливают детализированное рассуждение, и при отсутствии ограничений на длину ответы монотонно увеличиваются в сторону (панель c, отсечение с шагом 40). Этот взрывной рост ответов в конечном итоге снижает точность до поскольку ответы обрываются в процессе рассуждения.
(4) Полный TT-OPD (красные кривые). Добавление косинусной награды с контролем длины устраняет взрыв ответов (панель c), позволяя условным подсказкам по результатам эффективно работать на протяжении более 60 шагов — достигая устойчивой немонотонной сходимости к (панель a) со стабильными витками (–, Панель б). Каждый компонент направлен на устранение отдельного типа сбоев: EMA предотвращает коллапс KL, подсказки результатов обеспечивают сигнал, учитывающий исход, а косинусная награда предотвращает взрывной рост ответов..
Данная динамика подтверждает, что коллапс в многошаговых взаимодействиях (multi-turn collapse) является агент-специфичный режим отказа, отсутствующий в однократных настройках OPD (Zhao et al., 2026; Yang et al., 2026), где длины ответов естественным образом ограничены, а структура реплик не имеет значения.
7 Обсуждение и Заключение
Несколько направлений расширяют данную работу. Во-первых,, модели вознаграждения на уровне процессов (PRMs) (Lightman et al., 2024; Uesato et al., 2022) могли бы заменить или дополнить разреженное терминальное вознаграждение обратной связью на уровне хода, потенциально ускоряя распределение кредитов в длинных эпизодах. Во-вторых, подсказки, обусловленные исходом, можно расширить до иерархическое кондиционирование, где промежуточные подцели (например, корректный диагноз перед лечением) обеспечивают специфичные для этапа обучающие сигналы. В-третьих, разбавление градиентного сигнала, выявленное в Утверждении E.2 предполагает, что адаптивное взвешивание вознаграждения—динамически регулируемый на основе отношения сигнал-шум (SNR) для каждого компонента в процессе обучения — может снизить размытие точности-формата без ручной настройки. В-четвертых, масштабирование TT-OPD до крупные модели и более длинные эпизоды (например, 20+ специализированных консультаций) позволили бы проверить, обладает ли EMA восстанавливающей силой (Предложение E.1) остается эффективным по мере роста пространства политик. Наконец, развертывание Healthcare AI GYM с оценка с участием человека—где клиницисты оценивают поведение агента за пределами автоматизированных метрик — это позволит сократить разрыв между симулированной и реальной клинической полезностью.
Мы представили всестороннее эмпирическое исследование многошагового агентного RL для медицинского ИИ. В ходе систематических экспериментов на Healthcare AI GYM на 18 тестовых наборах данных мы выделили четыре ключевых результата: (1) TT-OPD демонстрирует широкую компетентность, достигая наилучших показателей на 10 из 18 тестов, включая задачи с множественным выбором (MedQA 87,1%, MedMCQA 66,2%), визуальные вопросы (PathVQA 45,3%, Quilt-VQA 30,7%), анализ электронных медицинских карт (MIMIC-III 62,7%, eICU 57,1%) и генеративные вопросы с развернутыми ответами (LiveQA 62,5%, MedicationQA 60,9%), сохраняя стабильность обучения при контролируемой длине ответов (5,7–9,3 тыс. токенов) и устойчивом использовании инструментов в многоходовом режиме (7,0–7,4 шагов); (2) Vanilla GRPO показывает высокую точность обучения (+9,4 п.п., достигая пика в 62,0% на шаге 55) и лидирует в задачах генеративных вопросов с высокой нагрузкой на знания (KQA-Golden 65,3%, KQA-Silver 64,9%), однако страдает от колебаний длины ответов (7,7–10,8 тыс. токенов), что может быть характерно для различных алгоритмов RL; (3) Три взаимосвязанных режима сбоя — взрывной рост ответов, коллапс многоходового взаимодействия и нестабильность дистилляции — специфичны для многоходового агентного RL и отсутствуют в одноходовых сценариях; и (4) фундаментальный разрыв между агентным и текстовым переносом: многоходовая агентная оценка вносит систематические накладные расходы в тестах на воспроизведение знаний (MMLU: 83,8% logprob 60,6% Base+AR 65.5% TT-OPD), где параметрические знания модели остаются неизменными, но многократные вызовы инструментов приводят к ошибкам преобразования формата. Оба Healthcare AI GYM окружающая среда и конвейер обучения общедоступны.
Ссылки
- Нори и соавт. (2023) Nori, H., и др.. Возможности GPT-4 в решении медицинских задач. Препринт arXiv:2303.13375, 2023.
- Singhal et al. (2023) Сингал, К. и др.. К достижению экспертного уровня в ответах на медицинские вопросы с помощью больших языковых моделей. Препринт arXiv:2305.09617, 2023.
- Чен и соавт. (2024) Чен, Дж., и др.. HuatuoGPT-o1: В сторону медицинского сложного рассуждения с использованием LLMs. Препринт arXiv:2412.18925, 2024.
- Jin et al. (2021) Джин, Д. и др.. Какое заболевание у данного пациента? Крупномасштабный набор данных для ответов на вопросы в открытой предметной области на основе медицинских экзаменов. Прикладные науки, 2021.
- Hendrycks et al. (2021) Хендрикс, Д., Бёрнс, К., Басарт, С., Цзоу, А., Мазейка, М., Сонг, Д., и Стейнхардт, Дж.. Измерение масштабного многозадачного понимания языка. ICLR, 2021.
- Pal et al. (2022) Пал, А., Умапати, Л. К., и Санкарасуббу, М.. MedMCQA: Крупномасштабный мультидисциплинарный набор данных с множественным выбором для вопросно-ответных систем в медицинской области. CHIL, 2022.
- Thirunavukarasu et al. (2023) Тирунавукарасу, А. Дж., Тинг, Д. С. Дж., Элангован, К., Гутьеррес, Л., Тан, Т. Ф., и Тинг, Д. С. У.. Крупные языковые модели в медицине. Nature Medicine, 29(8):1930–1940, 2023.
- Яо и соавт. (2023) Яо, С., Чжао, Дж., Ю, Д., Ду, Н., Шафран, И., Нарасимхан, К., и Цао, Й.. ReAct: Синергия логического рассуждения и действий в языковых моделях. ICLR, 2023.
- Вэй и соавт. (2022) Вэй, Дж., Ван, X., Схуурманс, Д., и др.. Метод Chain-of-Thought Prompting стимулирует логические рассуждения в больших языковых моделях (Large Language Models).. NeurIPS, 2022.
- Ванг и др. (2023) Ванг, X., Вэй, Дж., Схуурманс, Д., и др.. Самостоятельная согласованность улучшает цепочечные рассуждения в языковых моделях. ICLR, 2023.
- Шен и др. (2026) Шэнь, У., и др.. MedOpenClaw: Аудируемые агенты медицинской визуализации с логическим выводом на основе необработанных полных исследований. Препринт arXiv:2603.24649, 2026.
- Шик и соавт. (2023) Шик, Т., и др.. Toolformer: Языковые модели могут самостоятельно обучаться использованию инструментов. NeurIPS, 2023.
- Шульман и др. (2017) Шульман Дж., Вольски Ф., Дхаривал П., Радфорд А. и Климов О.. Алгоритмы оптимизации проксимальной политики. arXiv препринт arXiv:1707.06347, 2017.
- Шао и др. (2024)) Шао, З., и др.. DeepSeekMath: Расширение границ математического мышления в открытых языковых моделях. Препринт arXiv, 2024.
- Оуян и др. (2022) Оуян Л., У Дж., Цзян X. и др.. Обучение языковых моделей следованию инструкциям с использованием обратной связи от человека. NeurIPS, 2022.
- Шмидгалл и др. (2025) Шмидгалл, С., и др.. AgentClinic: Мультимодальный бенчмарк для оценки ИИ в смоделированных клинических средах. Препринт arXiv, 2025.
- Li et al. (2024) Ли, Дж., Ван, С., Чжан, М., и др.. Agent Hospital: Симулякр больницы с эволюционирующими медицинскими агентами. arXiv препринт arXiv:2405.02957, 2024.
- Xu et al. (2026) Сюй, Р., и др.. MedAgentGym: Масштабируемая агентная среда обучения для кодоцентрического анализа в биомедицинской науке о данных. ICLR, 2026.
- Lightman et al. (2024) Лайтман, Х., Косаражу, В., Бурда, Й., и др.. Давайте проверим шаг за шагом. ICLR, 2024.
- Uesato et al. (2022) Uesato, J., Kushman, N., Kumar, R., Song, F., Siegel, N., Wang, L., Creswell, A., Irving, G., and Higgins, I. Решение математических задач с процессно-ориентированной и результативной обратной связью. Препринт arXiv:2211.14275, 2022.
- Ши и др. (2024) Ши В., Юань М., У Дж., Ван К. и Фэн Ф.. Прямая оптимизация многоходовых предпочтений для языковых агентов. Препринт arXiv:2406.14868, 2024.
- Jung et al. (2025) Юнг С., Ли Д., Ли С. и др.. DiaTool-DPO: Оптимизация прямых предпочтений для многошаговых инструментально-расширенных больших языковых моделей. arXiv препринт arXiv:2504.02882, 2025.
- Чжао и соавт. (2026)) Чжао, С., и др.. Самообучаемый рассуждатель: Он-политичное самообучение для больших языковых моделей. Препринт arXiv:2601.18734, 2026.
- Ян и др. (2026) Ян, C., и др.. Self-Distilled RLVR. Препринт arXiv:2604.03128, 2026.
- Сонг и Чжэн (2026) Сон, М. и Чжэн, М.. Обзор методов обучения на политике для больших языковых моделей. Препринт arXiv:2604.00626, 2026.
- Тарвайнен и Валпола (2017) Тарвайнен, А. и Валпола, Х.. Средние учителя — лучшие образцы для подражания: усреднённые по весам целевые показатели согласованности улучшают результаты полуконтролируемого обучения. NeurIPS, 2017.
- Йео и соавт. (2025) Йео, У., и др.. Демистификация длинных цепочек рассуждений в LLM. arXiv препринт arXiv:2502.03373, 2025.
- Yu et al. (2025) Юй, К., и др.. DAPO: Масштабируемая система обучения с подкреплением для LLM с открытым исходным кодом. arXiv препринт arXiv:2503.14476, 2025.
- Лю и соавт. (2025) Лю, З., и др.. Понимание обучения по типу R1-Zero: критический взгляд. COLM, 2025.
- Чжэн и др. (2025) Чжэн, К., Лю, С. и др.. GSPO: Group Sequence Policy Optimization. arXiv препринт arXiv:2507.18071, 2025.
- Муллаппилли и др. (2026) Муллаппилли, С. С., и др.. MediX-R1: Открытая медицинская система Reinforcement Learning. Препринт arXiv:2602.23363, 2026.
- Цинь и др. (2024) Цинь, Я., и др.. ToolLLM: Обучение больших языковых моделей работе с более чем 16000 реальных API. ICLR, 2024.
- Льюис и др. (2020) Льюис, П., Перес, Э., Пиктус, А. и др.. Извлечение-дополненная генерация для задач NLP, требующих знаний. NeurIPS, 2020.
- Jin et al. (2023) Джин К., Ким В., Чен К., Комо Д. К., Еганова Л., Уилбур У. Дж. и Лу З.. MedCPT: Контрастные предобученные Transformers с крупномасштабными журналами поиска PubMed для нулевого поиска биомедицинской информации. Биоинформатика, 39(11), 2023.
- Rafailov et al. (2023) Рафаилов, Р., Шарма, А., Митчелл, Э., Эрмон, С., Мэннинг, К. Д., и Финн, К.. Direct Preference Optimization: Ваша языковая модель — это на самом деле модель вознаграждения. NeurIPS, 2023.
- Хинтон и соавт. (2015) Hinton, G., Vinyals, O., and Dean, J. Дистилляция знаний в нейронной сети. Препринт arXiv:1503.02531, 2015.
- Li et al. (2026) Ли, Г., и др.. Объединение групповой относительной и самодистилляции в оптимизации политик через маршрутизацию выборок. Препринт arXiv:2604.02288, 2026.
- Санг и др. (2026) Санг, Х. и др.. CRISP: Сжатое рассуждение посредством итеративного самообучения стратегии. Препринт arXiv:2603.05433, 2026.
- Ся и др. (2026) Ся, Ю., и др.. Обучение подсказкам для обучения с подкреплением. Препринт arXiv:2604.00698, 2026.
- Мухтар и соавт. (2026) Мухтар, Д., и др.. Дополняющее обучение с подкреплением. Препринт arXiv:2603.17621, 2026.
- Асаи и др. (2023) Асаи А., Ву З., Ван Ю., Сил А., Хажиширзи Х.. Self-RAG: Обучение извлечению, генерации и критике через саморефлексию. Препринт arXiv:2310.11511, 2023.
- Jeong et al. (2024) Чон, М., Сон, Дж., Сун, М. и Кан, Дж.. Улучшение медицинского обоснования через поиск и саморефлексию с использованием поисково-усиленных больших языковых моделей. Биоинформатика, 40(Приложение_1):i119–i127, 2024. ISMB 2024.
- Zelikman et al. (2022) Зеликман, Э., У, Й., Му, Дж., и Гудман, Н.. STaR: Наращивание рассуждений с помощью рассуждений. В NeurIPS, 2022.
- Yuan et al. (2025) Юань, С., Чэнь, Ц., Си, Ц., Е, Дж., Ду, Ц., и Чэнь, Дж.. Agent-R: Обучение языковых моделей-агентов рефлексии через итеративное самообучение. Препринт arXiv:2501.11425, 2025.
- Li et al. (2025) Ли, П., Гао, З., Чжан, Б. и др.. Итеративное исследование использования инструментов для мультимодальных агентов посредством пошаговой настройки предпочтений. Препринт arXiv:2504.21561, 2025.
- Cao et al. (2025) Цао, З., Ван, Р., Ян, Й. и др.. PGPO: Улучшение рассуждений агентов с помощью оптимизации предпочтений, управляемой псевдокод-планированием. Препринт arXiv:2506.01475, 2025.
- Чен и др. (2025) Чен, С., Чжао, М., Сюй, Л. и др.. DEPO: Оптимизация предпочтений с двойной эффективностью для LLM-агентов. Препринт arXiv:2511.15392, 2025.
- Шен и соавт. (2024) Шэн Г., Цао Ц., Гао С. и др.. veRL: Открытый унифицированный фреймворк для обучения с подкреплением в области больших языковых моделей. Препринт arXiv:2409.19951, 2024.
- Тауэрс и др. (2024) Тауэрс, М. и др.. Gymnasium: Стандартный интерфейс для сред обучения с подкреплением. Препринт arXiv:2407.17032, 2024.
- Джонсон и соавт. (2016) Джонсон, А. Э. У., Поллард, Т. Дж., Шен, Л. и др.. MIMIC-III, свободно доступная база данных по интенсивной терапии. Научные данные, 3:160035, 2016.
- Команда Qwen (2025) Команда Qwen. Qwen3.5-9B. https://huggingface.co/Qwen/Qwen3.5-9B, 2025.
- Ян и др. (2024) Ян, А., Ян, Б., Хуэй, Б. и др.. Qwen2.5 Технический отчет. Препринт arXiv: arXiv:2412.15115, 2024.
- Ян и др. (2023) Ян, С. и др.. Переосмысление бенчмарков и проблемы контаминации в языковых моделях с перефразированными выборками. arXiv препринт, 2023.
- Лау и соавт. (2018) Лау, Дж. Дж., Гайен, С., Бен Абача, А. и Демнер-Фушман, Д.. Набор данных клинически сгенерированных визуальных вопросов и ответов о радиологических изображениях. Научные данные, 5:180251, 2018.
- He et al. (2020) Хе, X., Чжан, Y., Моу, L., Син, E., и Се, P. PathVQA: 30000+ вопросов для медицинского визуального ответа на вопросы. Препринт arXiv:2003.10286, 2020.
- Лю и др. (2021) Лю, Б., Чжань, Л.-М., Сюй, Л., Ма, Л., Ян, Я., и У, X.-M. SLAKE: Семантически размеченный набор данных с расширенными знаниями для медицинского визуального вопроса-ответа. ISBI, 2021.
- Pollard et al. (2018) Поллард, Т. Дж., Джонсон, А. Э. У., Раффа, Дж. Д., Сели, Л. А., Марк, Р. Г., и Бадави, О.. База данных eICU Collaborative Research Database — это открытая многопрофильная база данных для исследований в области интенсивной терапии.. Научные данные, 5:180178, 2018.
- Бен Абача и соавт. (2019) Бен Абача, А., Агихтейн, Э., Пинтер, Й., и Демнер-Фушман, Д.. Обзор задачи автоматического ответа на медицинские вопросы на TREC 2017 LiveQA. TREC, 2019.
- Амари (1998) Амари, С.. Естественный градиент эффективен в обучении. Нейронные вычисления, 10(2):251–276, 1998.
- Поляк и Юдицкий (1992) Поляк Б. Т. и Юдитский А. Б.. Ускорение стохастической аппроксимации методом усреднения. SIAM Journal on Control and Optimization, 30(4):838–855, 1992.
- Лин (2004) Лин, C.-Y.. ROUGE: Пакет для автоматической оценки рефератов. Семинар ACL по автоматическому реферированию текстов, 2004.
- OpenAI (2025) OpenAI. HealthBench: Бенчмарк для оценки ИИ, связанного со здоровьем. https://huggingface.co/datasets/openai/healthbench-professional, 2025.
- Zhang et al. (2023) Чжан, Й., Ван, Х., и др.. PMC-VQA: Визуальный вопросно-ответный анализ изображений из PubMed Central. arXiv препринт, 2023.
- Абача и др. (2021) Бен Абача, А., Хасан, С. А., и Демнер-Фушман, Д.. VQA-Med: Обзор задачи медицинского визуального ответа на вопросы на ImageCLEF 2021. CLEF Working Notes, 2021.
- Ху и др. (2022) Ху, З., Чжан, Й. и др.. Quilt-VQA: Визуальный вопросно-ответный анализ гистопатологических изображений. Препринт arXiv, 2022.
- Manes et al. (2024) Манес И., Ронн Н., Коэн Д., Бер Р. И., Горовитц-Куглер З., Становски Г.. K-QA: Бенчмарк для вопросов и ответов в медицинской практике. Препринт arXiv:2401.14493, 2024.
- Абача и др. (2019) Абача, А. Б., Мрабе, Й., Шарп, М., Гудвин, Т. Р., Шушан, С. Е., и Демнер-Фушман, Д.. Преодоление разрыва между вопросами потребителей о лекарствах и достоверными ответами. В Труды MedInfo, 2019.
- Jeong et al. (2024) Чон, М., Хван, Х., Юн, С., Ли, Т., и Кан, Дж.. OLaPH: Улучшение достоверности в биомедицинских развернутых ответах на вопросы. Препринт arXiv:2405.12701, 2024.
Приложение А Healthcare AI GYM: Детальное построение
Данное приложение содержит исчерпывающие сведения о проектировании, реализации и построении Healthcare AI GYM, всего 30 тысяч строк кода в 10 клинических областях.
A.1 Интерфейс Gymnasium
Тренажер искусственного интеллекта для здравоохранения реализует стандартный API Gymnasium через BioAgentGymEnv(gym.Env):
-
•
Пространство наблюдений: spaces.Text(max_length=100000) содержащий историю переговоров, результаты инструментов и информацию о пациенте.
-
•
Пространство действий: spaces.Text(max_length=10000) представляющий либо вызов инструмента JSON, либо ответ на естественном языке.
-
•
Эпизодический поток: сброс() загружает задачу и возвращает системный промпт + тикет пациента; шаг(действие) разбирает вызовы инструментов, выполняет их и возвращает наблюдения. Эпизод завершается, когда отправить_ответ() называется или max_turns достигается.
-
•
Вознаграждение: Скаляр из 5 измерений при завершении эпизода (Eq. МЕТКА: eq:reward).
Реестр доменов лениво загружает 10 доменных модулей, каждый из которых предоставляет get_environment() и get_tasks() Функции. Задачи загружаются из предметно-ориентированных JSON-файлов и нормализуются к единой схеме с детерминированными ID посредством хеширования MD5..
А.2 Проектирование домена
Таблица 2 обобщает 10 клинических областей. Каждая область следует модульной структуре.: data_model.py (Pydantic схемы), tools.py (ToolKitBase подкласс), environment.py (точка входа в домен) и файлы данных (db.json, tasks.json, policy.md).
| Область | Клиническая направленность | Задачи | Инструменты | LoC | Ключевые возможности |
|---|---|---|---|---|---|
| Клиническая диагностика | Дифференциальная диагностика | 5 | 25 | 1,753 | Анамнез, лабораторные исследования, дифференциальная диагностика, назначение лекарств |
| Медицинский вопросно-ответный анализ (Medical QA) | Основанный на доказательствах вопросно-ответный анализ | 1,000 | 16 | 683 | Поиск в PubMed, анализ доказательств |
| Взаимодействие лекарственных средств | Фармаконадзор | 5 | 18 | 1,024 | DDI, CYP450, альтернативы |
| Управление электронными медицинскими записями (EHR) | Электронные медицинские записи | 15 | 22 | 947 | MIMIC-III/IV, SOFA/APACHE |
| Триаж и экстренная помощь | Экстренная медицина | 20 | 20 | 1,344 | ABC, ESI, GCS, qSOFA, HEART |
| Визуальная диагностика | Медицинская визуализация | 8 | 17 | 1,343 | Анализ изображений, сходство случаев |
| Радиологическое заключение | Структурированная отчётность | 20 | 17 | 549 | BI-RADS, TI-RADS, Fleischner |
| Психиатрия | Психическое здоровье | 20 | 20 | 639 | MSE, PHQ-9, GAD-7, Columbia |
| Акушерство | Медицина матери и плода | 20 | 20 | 632 | CTG, Bishop score, ACOG |
| Кросс-доменный | Многофазные пути | 25 | Var. | — | 6 направлений (боль в груди, ДКА и т. д..) |
| Total | 3,6 тыс.+† | 135‡ | 8,9 тыс. |
†3,631 инстанцированных задач из исходных задач + AutoTaskGenerator расширение. Из них 2,657 используются для обучения с подкреплением (RL), а 307 — для валидации (см. §5). ‡135 уникальных инструментов зарегистрировано в tool_config_full.yaml; количество объектов по доменам включает общие KnowledgeTools.
Структура задачи
Каждая задача представляет собой объект JSON, содержащий: (1) сценарий пациента билет, (2) ожидаемые взаимодействия с инструментами сравнить_аргументы указание, какие аргументы должны совпадать, (3) утверждения на естественном языке для оценки качества и (4) основа вознаграждения массив выбора между ДЕЙСТВИЕ и NL_ASSERTION оценка. Задачи поступают из трех источников: экспертно отобранные исходные задачи (1 138 из различных областей), AutoTaskGenerator расширение за счет внешних эталонных данных (MCQAConverter, VQAConverter, EHRConverter) и извлечения знаний, что привело к созданию 3 631 конкретизированной задачи после валидации человеком.
Конвейер генерации задач
[[ERROR]] The... AutoTaskGenerator преобразует внешние эталонные данные и извлекает знания из источников через пять конвертеров: (1) MCQAConverter обрабатывает 8,9 тыс. вопросов из 8 тестовых наборов MCQA (MedQA, MedMCQA, 6 подмножеств MMLU); (2) MedLFQAConverter обрабатывает 4.9K вопросов и ответов в длинной форме; (3) VQAConverter загружает 6 наборов данных для визуального вопросно-ответного взаимодействия (25K изображений); (4) EHRConverter извлекает эпизоды госпитализации из MIMIC-III/IV; (5) KnowledgeMiner генерирует пары вопрос-ответ (QA) на основе извлечения фрагментов текста с использованием FTS5. Каждый конвертер назначает специализированные инструменты для конкретной предметной области и создает стабильные идентификаторы (ID) для обеспечения воспроизводимости..
Междоменные пути
Двигатель клинических путей определяет 6 многофазных клинических маршрутов (боль в груди, диабетическая экстренная ситуация, код инсульта, сепсис-комплекс, послеоперационное осложнение, детская лихорадка). Каждый путь представляет собой последовательность PathwayPhase объекты, определяющие активную область, требуемые действия, NL-утверждения, условия перехода и необязательные флаги временного давления. Оценка проводится поэтапно и в целом..
Доменные модели данных
Каждая предметная область определяет Pydantic BaseModel схемы, наследуемые от общего БД класс, поддерживающий сериализацию, хеширование и генерацию схемы. Например, Клиническая диагностика определяет Пациент (демографические данные, аллергии с указанием степени тяжести, лекарственные препараты, состояния, жизненно важные показатели, результаты лабораторных исследований, клинические заметки, семейный/социальный анамнез), LabResult (с референсными диапазонами и флагами), Клиническое руководство, и Взаимодействие лекарственных средств. Управление электронными медицинскими записями (EHR) отражает схему MIMIC с Поступление, Пребывание в отделении интенсивной терапии (ОИТ), LabEvent, VitalEvent, Назначение лекарственного препарата, и ClinicalScore (SOFA/APACHE/SAPS/NEWS).
А.3 Реализация системы инструментов
Фреймворк Decorator
Инструменты регистрируются через @является_инструментом(ToolType) декоратор, поддерживающий четыре типа: ЧИТАТЬ (запросы), НАПИСАТЬ (модификации состояний), ДУМАТЬ (внутренние рассуждения), и УНИВЕРСАЛЬНЫЙ (). Метакласс _ToolKitMeta собирает все декорированные методы в процессе создания класса. ToolDefinition.from_method() автоматически анализирует сигнатуры методов и строки документации для генерации схем вызовов функций, совместимых с OpenAI. CompositeToolKit объединяет специализированные инструменты с общими KnowledgeTools используя семантику first-wins.
Исполнение инструментов
Окружающая среда шаг() метод анализирует действия агента в формате JSON, проверяет названия инструментов по зарегистрированному набору инструментов, выполняет через инструменты.использовать_инструмент(название, **аргументы)), и возвращает результаты в виде Сообщение инструмента объекты. Некорректный JSON или неизвестные названия инструментов возвращают сообщения об ошибках вместо завершения эпизода..
Репрезентативные инструменты домена
Специализированные инструменты охватывают шесть категорий в девяти областях (всего 135 уникальных инструментов).): Поиск знаний (6 инструментов): запрос индексированной коллекции текстовых фрагментов с помощью BM25 через SQLite. Клиническая оценка (22 инструмента): валидированные шкалы оценки (APACHE-II, CURB-65, Wells и др.).). Доступ к данным пациентов: история, показатели жизнедеятельности, лабораторные данные, лекарственные препараты, аллергии по доменам. Клинические действия: назначение анализов, выписка лекарств, фиксация диагнозов. Рассуждение: дифференциальная диагностика, анализ ответов, сравнение методов лечения. Документация: клинические записи, выписные эпикризы.
Приложение A.4 База знаний: 828 тыс. фрагментов
База знаний реализована в виде базы данных SQLite FTS5 (Full-Text Search v5) с ранжированием BM25.:
-
•
Схема: CREATE VIRTUAL TABLE passages_fts USING fts5(doc_id, source, title, content, category, dataset_name, tokenize=’porter unicode61’)
-
•
Источники: MedCPT evidence (581 тыс. отрывков из PubMed/PMC), биомедицинские пары вопрос-ответ (122 тыс.), сгенерированные отрывки (83 тыс.), MedInstruct (52 тыс.) — всего 828 473 проиндексированных отрывка.
-
•
Поиск: Токенизация с использованием стеммера Портера, ранжирование релевантности BM25, генерация сниппетов с выделением терминов, булевы операторы запросов.
-
•
Википедия: Офлайн-индекс FTS5 для более чем 26 млн статей (188 ГБ) с постраничной выборкой на основе смещений
-
•
Доступ: Потокобезопасный синглтон MedicalKnowledgeBackend с режимом WAL и ленивой инициализацией
Все инструменты поиска знаний основаны на одной и той же MedicalKnowledgeBackend одиночка с потокобезопасным доступом к SQLite в режиме WAL.
Приложение A.5 5D реализация вознаграждения
Система вознаграждения (400 строк) реализует каждое измерение в виде композируемых функций:
Точность ().
Три варианта: (1) точное соответствие для MCQ (1.0 при правильном ответе, 0.0 в противном случае), (2) мягкий используя ROUGE-1 (Lin, 2004) + BLEU-1, перекрытие токенов F1 для открытых ответов, (3) bertscore использование BiomedBERT для семантического сходства с мягким откатом.
Качество процесса ()
Взвешенная комбинация: 60% покрытие (доля ожидаемых инструментов, вызванных с соответствующими аргументами), 20% разнообразие (уникальные сигнатуры инструментов / общее количество вызовов), 20% тщательность (использованные уникальные названия инструментов). Кроме того, оценка на основе рубрик (вес 70% при наличии рубрики) проверяет обязательные элементы, обязательные инструменты и запрещенные элементы..
Безопасность ()
Правило-ориентированный SafetyViolation обнаружение с более чем 50 шаблонами нарушений по 5 уровням серьезности, каждый из которых соотносится с принципом этики AMA (непричинение вреда, благодеяние, автономия). Критические нарушения (уровень серьезности 5: игнорирование противопоказаний, опасная дозировка, пропуск экстренного случая) ограничивают общее вознаграждение значением 0.1; серьезные нарушения (уровень серьезности 4) применяют штраф.
Формат ()
Градуированная оценка: 1.0 за валидный JSON с имя и аргументы; 0.8 для JSON в блоках кода; 0.5 для частичной структуры; 0.0 для неверного формата. Финальная проверка учитывает связность ответа. (10 символов).
Когерентность ()
Проверяет логическую согласованность, отсутствие противоречий и четкие клинические выводы..
Интеграция GRPO
TRL-совместимая оболочка grpo_reward_fn() вычисляет все измерения вознаграждения и возвращает взвешенную скалярную величину для использования с GRPOTrainer.
Приложение A.6 Поведенческие политики
Каждая область включает в себя политика.md файл, определяющий поведенческие рекомендации, внедряемые как системное приглашение. Политики определяют: (1) основные принципы (безопасность пациента прежде всего, доказательная медицина, системный подход), (2) руководства по использованию инструментов (например, «всегда начинать с получить_информацию_о_пациенте()”, “проверить наличие аллергии перед назначением"), и (3) ограничения (например, "НЕ ставьте диагноз без анализа данных пациента", "если вопрос выходит за рамки компетенции, немедленно направьте к специалисту"). Эти правила обеспечивают соответствие поведения агента клиническим рекомендациям, оставаясь при этом специфичными для предметной области..
Приложение B Алгоритм TT-OPD
В данном разделе представлено детальное описание алгоритма Turn-Level Truncated On-Policy Distillation (TT-OPD), изложенного в Алгоритме 1. Рассматриваются процедура обучения, ключевые проектные решения и роль каждого компонента в стабилизации обучения агента в многошаговых взаимодействиях..
Настройка обучения.
TT-OPD функционирует в многошаговой среде, дополненной инструментами, где модель взаимодействует с внешней системой через последовательность шагов. На каждой итерации обучения из распределения задач выбирается пакет промптов, и для каждого промпта генерируется несколько траекторий через взаимодействие on-policy. Каждая траектория состоит из последовательности состояний и действий, где действия могут соответствовать вызовам инструментов или естественно-языковым ответам. Эпизод завершается при отправке финального ответа или достижении максимального числа шагов..
Генерация rollout и вознаграждение.
Для каждого промпта модель генерирует несколько траекторий, чтобы охватить разнообразные поведенческие паттерны в рамках текущей политики. Каждая траектория оценивается с использованием косинусного вознаграждения, которое отражает как корректность, так и семантическое соответствие эталонному решению. Данное вознаграждение обеспечивает плавный сигнал обучения, подходящий для задач долгосрочного рассуждения..
Для повышения эффективности обучения TT-OPD применяет стратегию динамической фильтрации, сохраняя только промпты, демонстрирующие смешанные результаты в ходе rollouts. Это гарантирует, что сохранённые выборки обеспечивают значимый контраст для обучения и исключает вырожденные обновления, вызванные однородно правильными или ошибочными траекториями..
Вычисление преимущества.
При наличии нескольких траекторий на один промпт TT-OPD вычисляет групповые относительные преимущества на основе значений вознаграждения. Данная формулировка устраняет необходимость в отдельной функции ценности и обеспечивает стабильную оптимизацию политики за счет нормализации производительности внутри каждой группы траекторий, специфичной для промпта..
Учитель-направленная дистилляция.
Ключевым компонентом TT-OPD является поэтапное дистиллирование на уровне ходов от модели-учителя. Модель-учитель формируется как экспоненциальное скользящее среднее параметров модели-ученика. Для каждой траектории в входные данные учителя добавляется контекст, связанный с результатом, что позволяет учителю генерировать более осознанные предсказания на уровне токенов..
Затем преподаватель вычисляет логарифмические вероятности действий на каждом шаге траектории. Чтобы предотвратить утечку информации, любой привилегированный контекст, добавленный для преподавателя, удаляется из выходных данных перед вычислением функции потерь дистилляции. Ученик обучается соответствовать поведению преподавателя на каждом шаге с помощью целевой функции расхождения Кульбака-Лейблера (KL). Такое пошаговое выравнивание побуждает ученика имитировать не только конечные ответы, но и промежуточные рассуждения, а также решения по использованию инструментов..
Совместная оптимизация.
Цель обучения сочетает обучение с подкреплением и дистилляцию. Компонент обучения с подкреплением стимулирует траектории с более высокими наградами, тогда как компонент дистилляции стабилизирует обучение, привязывая политику к учителю. Баланс между этими двумя целями контролируется скалярным коэффициентом. Такая совместная оптимизация позволяет модели исследовать улучшенные поведения, сохраняя согласованность в многошаговых рассуждениях..
EMA-обновление учителя.
Параметры учителя обновляются периодически с использованием экспоненциального скользящего среднего параметров ученика. Этот механизм обновления гарантирует плавное развитие учителя во времени и обеспечивает стабильную цель для дистилляции. Избегая резких изменений в политике учителя, TT-OPD снижает нестабильность, часто наблюдаемую в многозадачном обучении с подкреплением..
Вопросы устойчивости.
TT-OPD разработан для решения нескольких типов сбоев, возникающих при обучении многошаговых агентов. Во-первых, непрерывное согласование с учителем снижает риск коллапса политики, связанного с нестабильностью KL-дивергенции. Во-вторых, формулировка вознаграждения и динамика обучения неявно регулируют длину ответа, предотвращая неконтролируемый рост количества генерируемых токенов. В-третьих, пошаговый контроль сохраняет структуру многоступенчатых рассуждений, избегая вырождения в короткие или неполные последовательности взаимодействий..
В заключение, TT-OPD объединяет обучение с подкреплением on-policy со структурированной дистилляцией на уровне ходов в многопоточной среде. Такая конструкция обеспечивает стабильную оптимизацию, сохраняет промежуточные рассуждения и повышает надежность языковых агентов, усиленных инструментами..
Приложение C Инвентарь инструментов предметной области
Каждая область GYM предоставляет CompositeToolKit комбинирование специализированных инструментов с общими KnowledgeTools (PubMed search, извлечение доказательных данных, медицинская wiki). Все инструменты соответствуют формату вызова функций, совместимому с OpenAI..
| Область | R | W | G | Репрезентативные инструменты |
| Клиническая диагностика | 30 | 2 | 2 | получить жизненно важные показатели, заказ_лаб, генерировать_ddx |
| Медицинский вопросно-ответный сервис | 12 | 0 | 2 | анализировать варианты ответов, сравнение методов лечения |
| Визуальная диагностика | 6 | 0 | 2 | анализировать медицинское изображение, поиск_похожих_случаев |
| Взаимодействие лекарственных средств | 15 | 0 | 2 | проверить взаимодействие, проверить_метаболизм_cyp450 |
| Управление электронными медицинскими записями (EHR) | 18 | 3 | 2 | получить_тренд_лаборатории, написать_клиническую_заметку, оформить_заказ |
| Триаж и экстренная помощь | 16 | 3 | 2 | вычислить_gcs, скрин_сепсис |
| Радиологическое заключение | 7 | 1 | 2 | проанализировать результаты, получить_шаблон_отчета |
| Психиатрия | 12 | 0 | 2 | администрировать_phq9, оценить_риск_суицида |
| Акушерство | 17 | 1 | 2 | оценить состояние плода, интерпретация КТГ |
| Кросс-доменный | (двигатель pathway) | Мультидоменное упорядочивание клинических процессов | ||
Все инструменты возвращают выходные данные в формате, сериализуемом в JSON. думать() инструмент фиксирует внутренние рассуждения без внешних побочных эффектов. submit_answer() метка инструмента фиксирует завершение задачи и запускает оценку вознаграждения.
Приложение D Подробные экспериментальные результаты
D.1 Логарифмическая вероятность базового уровня (Text-Only)
Мы оцениваем базовые модели Qwen3.5-9B и обученные с помощью GRPO, используя оценку по логарифмической вероятности, которая вычисляет вероятность следующего токена для вариантов ответов (A–E) без доступа к инструментам или многошагового взаимодействия. Это обеспечивает базовый уровень параметрического знания. Точность GRPO по логарифмической вероятности практически идентична базовой модели (70.8% против 70.7% на MedQA, 83.9% против 83.8% на MMLU), что подтверждает параметрическое знание полностью сохраняется в ходе обучения с подкреплением с использованием LoRA (ранг 64, MLP + проекции внимания). Обучение с подкреплением изменяет поведенческие паттерны (использование инструментов, очередность действий), не затрагивая воспроизведение фактов.
D.2 Многозадачное агентное оценивание
Множественный выбор QA.
На MedQA (Jin et al., 2021), Базовая модель без инструментов достигает 70,7% по logprob. Добавление многошагового AgentRunner с 135 инструментами и базой знаний на 828K пассажей (Base+AR) позволяет достичь 78,8%, в то время как модели с обучением с подкреплением показывают результаты 85,5% (GRPO) и 87,1% (TT-OPD) — улучшение на +16,4 п.п., демонстрирующее, что обучение с подкреплением обеспечивает устойчивые преимущества, выходящие за рамки только ретривельной аугментации. На MMLU Medical (Hendrycks et al., 2021) (6 подтипов), многократная оценка снижает производительность: Base+AR 60.6% против logprob 83.8% (23,2 п.п.). Эти «агентные накладные расходы» отражают избыточные вызовы инструментов и ошибки преобразования форматов в процессе многошаговой обработки. TT-OPD (65,5%) частично восстанавливает производительность (+4,9 п.п. по сравнению с Base+AR), тогда как GRPO (60,1%) соответствует базовому уровню. MedMCQA (Pal et al., 2022) результаты демонстрируют, что TT-OPD достигает наилучшего показателя в 66.2%, превосходя как базовый logprob (63.8%), так и GRPO (58.0%).%).
Визуальный вопросно-ответный анализ (Visual QA).
На 6 тестовых наборах VQA модель TT-OPD демонстрирует наилучший или близкий к наилучшему результат в 5 из 6 случаев. На наборе VQA-RAD (Lau et al., 2018), Base+AR лидирует (63,2%), за ним следует TT-OPD (63,1%). PathVQA (He et al., 2020) показывает TT-OPD на уровне 45.3%, превосходя как базовый текст (40.5%), так и GRPO (41.5%). SLAKE (Liu et al., 2021) и PMC-VQA демонстрируют значительный разрыв между текстовой оценкой (79,0%, 57,9%†) и многозадачное агентное оценивание (30,6%, 35,1%), что согласуется с паттерном агентных накладных расходов. VQA-Med-2021 (15,2% TT-OPD) и Quilt-VQA (30,7% TT-OPD) представляют собой открытые визуальные QA-бенчмарки, где все методы показывают более низкие результаты, но TT-OPD стабильно лидирует.
Рассуждение на основе электронных медицинских записей (EHR).
MIMIC-III (Johnson et al., 2016) и eICU (Pollard et al., 2018) оцениваются с помощью балльной системы, основанной на действиях, измеряя, выполняет ли агент ожидаемые вызовы клинических инструментов (например,., получить_сводку_пациента, получить_результаты_анализов). TT-OPD демонстрирует наилучшие результаты (MIMIC-III 62,7%, eICU 57,1%), превосходя как Base+AR (62,1%, 55,9%), так и GRPO (61,1%, 55,5%). Базовая текстовая модель без инструментов показывает результаты 58,5% и 53,2% соответственно, что подтверждает, что рассуждение с использованием инструментов обеспечивает умеренное, но стабильное улучшение в структурированных задачах EHR..
Длинноформатный вопросно-ответный формат (Long-Form QA).
На 5 бенчмарках MedLFQA метод TT-OPD лидирует в 3 (LiveQA 62.5%, MedicationQA 60.9%, HealthSearchQA 45.3%), тогда как GRPO показывает лучшие результаты в задачах, требующих глубоких знаний (KQA-Golden 65.3%, KQA-Silver 64.9%). Эта дихотомия указывает на то, что более высокая пиковая точность обучения GRPO обеспечивает лучшее воспроизведение фактов в открытых условиях, тогда как стабильность TT-OPD способствует клиническому анализу. Все методы значительно превосходят базовый вариант Base text (например, LiveQA: 53.2% base). 62.5% TT-OPD), подтверждая, что обучение с подкреплением повышает качество развернутых ответов.
Приложение E Аналитические выводы
Мы анализируем три ключевые динамики, наблюдаемые в процессе обучения TT-OPD. Эти наблюдения применяют известные результаты теории естественного градиента и анализа EMA, чтобы обосновать, почему упрощенные варианты метода терпят неудачу, а полный метод достигает успеха; они не претендуют на формальную новизну..
Почему TT-OPD сходится немонотонно, а не расходится?
Отличительной особенностью обучения TT-OPD является немонотонный характер сходимости, видимый на рисунке. 4(a): точность возрастает, снижается, затем восстанавливается до более высокого уровня. Это не случайный шум — это отражает встроенный механизм самокоррекции, созданный EMA teacher..
Предложение E.1 (EMA как неявное снижение скорости обучения).
При обновлении учителя EMA с затуханием , градиент штрафа KL удовлетворяет (Amari, 1998), где является информацией Фишера. Эффективная скорость обучения для GRPO неявно снижается на коэффициент, пропорциональный , создание восстанавливающей силы: значительные изменения политики усиливают градиент KL, снижая последующие обновления. (Это следует из стандартной теории естественного градиента; мы приводим это здесь для обоснования обсуждения динамики обучения).)
Интуиция. Рассмотрим EMA-учителя как «память» о недавнем хорошем поведении. Когда обучаемый агент совершает значительное обновление политики (например, внезапно начинает предпочитать более короткие ответы), он отклоняется далеко от учителя. Расхождение Кульбака-Лейблера (KL) между ними увеличивается, что усиливает градиент, возвращающий обучаемого к распределению учителя. Это действует подобно пружине: чем дальше отклоняется обучаемый, тем сильнее восстанавливающая сила. И наоборот, когда обучаемый близок к учителю, градиент KL слаб, что позволяет доминировать сигналу вознаграждения GRPO и направлять обучаемого к повышению точности. Это чередование между исследованием, управляемым вознаграждением, и коррекцией, управляемой KL, приводит к характерной немонотонной сходимости. () видно на рисунке 4(а) и количественно оценены на рисунке 3.
Почему стандартный GRPO не улучшает качество текстовых вопросно-ответных систем, несмотря на повышение эффективности агентных задач??
Этот вопрос является ключевым для проблемы агентно-текстового переноса. Ответ заключается в том, как многомерные вознаграждения взаимодействуют с оценкой градиента..
Предложение E.2 (Разбавление градиентного сигнала).
С -многомерное вознаграждение , отношение сигнал-шум (SNR) компонента ’вклад в общее преимущество составляет , где является стандартным отклонением компонента вознаграждения и является стандартным отклонением общего вознаграждения. С нашими параметрами вознаграждения (, , , ), вклад точности в отношение сигнал-шум () доминирует формат (), создание Коэффициент разбавления 51:1. (Это прямое следствие линейности математического ожидания, применённого к нашим конкретным параметрам вознаграждения)..)
Интуиция. Представьте класс, где студент получает пять оценок (точность, качество процесса, безопасность, формат, согласованность), объединённых в один средний балл. Если оценка за формат почти не варьируется среди студентов (все получают почти идеальные баллы за формат),, ), формат почти не влияет на различение хороших и плохих rollout'ов — его градиентный сигнал "размывается" другими, более изменчивыми компонентами. Точность, обладающая высокой дисперсией (), доминирует в градиенте. Однако схема взвешивания 5D по-прежнему снижает эффективный градиент точности на по сравнению с вознаграждением, основанным только на точности. Это размытие объясняет, почему стандартный GRPO с 5D-вознаграждением не улучшает качество текстовых вопросно-ответных систем: градиент точности, хотя и доминирующий, недостаточен для преодоления уровня шума в пределах нескольких сотен шагов онлайн-обучения. TT-OPD компенсирует это, предоставляя дополнительный градиент дистилляции, обусловленный результатом, который напрямую кодирует информацию о корректности..
Почему EMA предотвращает пилообразный коллапс KL, наблюдаемый при периодических сбросах?
Периодические варианты сброса демонстрируют деструктивный паттерн: расхождение Кульбака—Лейблера накапливается по мере обучения ученика, а затем резко падает почти до нуля при перезаписи учителя. Мы формализуем, почему экспоненциальное скользящее среднее (EMA) устраняет этот режим сбоя..
Предложение E.3 (Ограниченность KL при экспоненциальном скользящем среднем (EMA)).
При обновлениях EMA со сдвигом на шаг и -Липшицев KL, стационарная дивергенция удовлетворяет , приводя к непрерывному росту KL. В отличие от этого, обновления с жесткой фиксацией порождают пилообразную KL с пиками, и резкие падения до нуля, разрушающие градиент дистилляции. (Эта граница следует из развертывания рекуррентного соотношения EMA) (Polyak & Juditsky, 1992); мы формулируем это для объяснения эмпирического контраста между динамикой EMA и периодического сброса.)
Интуиция. При периодических сбросах учитель представляет собой зафиксированный во времени снимок. По мере того как ученик совершенствуется, на каждом шаге расхождение Кульбака-Лейблера накапливается — распределения студента и учителя становятся всё более различными. При событии сброса (), учитель внезапно становится идентичным ученику, и KL-дивергенция падает до нуля. Это уничтожает весь сигнал дистилляции, который направлял ученика, заставляя обучение начинаться заново. Мы ясно наблюдаем это: на шаге 10 в вариант, KL снижается с 2.637 до 0.343, а точность начинает монотонно снижаться вскоре после этого. С EMA (), учитель непрерывно поглощает небольшую долю улучшений ученика. KL-дивергенция никогда не снижается резко — она плавно возрастает от 0.001 до 1.063 за 60 шагов, обеспечивая стабильный и постепенно усиливающийся регуляризующий сигнал в течение всего обучения.
Приложение F Гиперпараметры обучения
| Параметр | GRPO | TT-OPD |
|---|---|---|
| Модель & тонкая настройка | ||
| Базовая модель | Qwen3.5-9B | Qwen3.5-9B |
| Точная настройка | Full-param (FSDP) | Full-param (FSDP) |
| FSDP offload | параметр + оптимизатор | параметр + оптимизатор |
| Точность | bf16 | bf16 |
| Оптимизация | ||
| Скорость обучения | ||
| Планировщик скорости обучения | Постоянная | Постоянная |
| Шаги разогрева | 0 | 0 |
| Максимальная норма градиента | 1.0 | 1.0 |
| Размер пакета при обучении | 8 | 8 |
| Микропакет (на GPU)) | 1 | 1 |
| Эпохи | 3 | 1 |
| Rollout & RL | ||
| Поколений на промпт () | 3 | 3 |
| KL-штраф () | 0.01 | 0.01 |
| Максимальная длина промпта | 8,192 | 8,192 |
| Максимальная длина ответа () | 12,288 | 12,288 |
| Максимальное количество взаимодействий с ассистентом | 5 | 5 |
| Дистилляция TT-OPD | ||
| Коэффициент дистилляции () | – | 4.0 |
| Экспоненциальное скользящее затухание (EMA decay) () | – | 0.995 |
| интервал обновления EMA | – | 5 шагов |
| Интервал печати на бумажный носитель | – | 30 шагов |
| Косинус / | – | 1.1 / 0.7 |
| Косинус | – | |
Приложение G Набор тестовых данных
| Категория | Бенчмарк | Образцы | Метрика |
| Текст: Вопросно-ответные системы (Text QA) | MedQA (USMLE) (Jin et al., 2021) | 1,273 | Точность |
| MedMCQA (Pal et al., 2022) | 4,183 | Точность | |
| MMLU-Clinical Knowledge (Hendrycks et al., 2021) | 265 | Точность | |
| MMLU-Professional Medicine | 272 | Точность | |
| MMLU-Anatomy | 135 | Точность | |
| MMLU-Medical Genetics | 100 | Точность | |
| MMLU-College Biology | 144 | Точность | |
| MMLU-College Medicine | 173 | Точность | |
| Визуальный вопросно-ответный анализ (Vision QA) | VQA-RAD (Lau et al., 2018) | 451 | Точность |
| SLAKE (Liu et al., 2021) | 1,061 | Точность | |
| PathVQA (He et al., 2020) | 6,719 | Точность | |
| PMC-VQA (Zhang et al., 2023) | 1,996 | Точность | |
| VQA-Med-2021 (Abacha et al., 2021) | 425 | Точность | |
| Quilt-VQA (Hu et al., 2022) | 985 | Точность | |
| Длинноформатный вопросно-ответный формат (Long-Form QA) | KQA Golden (Manes et al., 2024) | 201 | ROUGE-L / Hall. / Comp. |
| LiveQA (Ben Abacha et al., 2019) | 100 | ROUGE-L / Hall. / Comp. | |
| MedicationQA (Abacha et al., 2019) | 666 | ROUGE-L / Hall. / Comp. | |
| HealthSearchQA | 3,077 | ROUGE-L / Hall. / Comp. | |
| KQA Silver (Manes et al., 2024; Jeong et al., 2024) | 904 | ROUGE-L / Hall. / Comp. | |
| Электронная медицинская карта (EHR) | MIMIC-III (Johnson et al., 2016) | 5,000 | Балл действия + Вознаграждение |
| eICU (Pollard et al., 2018) | 5,000 | Балл действия + Вознаграждение |
Приложение H Таксономия нарушений безопасности
| Серьезность | Категория | Пример | Эффект вознаграждения |
|---|---|---|---|
| 5 | Противопоказание проигнорировано | пенициллин пациенту с аллергией | Ограничение на уровне 0.1 |
| 5 | Пропущенная чрезвычайная ситуация | Не удалось распознать STEMI | Ограничение на уровне 0.1 |
| 5 | Опасное дозирование | 10-кратная рекомендуемая доза | Ограничение на уровне 0.1 |
| 4 | Пропущенное DDI | Неучтенное взаимодействие варфарина и НПВП | |
| 4 | Сфабрикованные доказательства | Цитирование несуществующего исследования | |
| 3 | Неполное обследование | Нет подтверждающего теста | |
| 3 | Несоблюдение рекомендаций | Отклонено без обоснования | |
| 2 | Отсутствие последующего наблюдения | Отсутствие плана последующих действий | |
| 1 | Стилевая проблема | Несогласованность форматирования |
Приложение I Использование LLM
Мы используем Claude Opus 4.6 для проведения экспериментов и обучения, разработки общей концепции рукописи, проверки грамматики сгенерированных предложений, а также для проверки библиографических ссылок..
Приложение J Примерные траектории
Мы представляем репрезентативные многошаговые траектории из модели TT-OPD (шаг 60), иллюстрирующие паттерны агентного мышления, усвоенные в ходе обучения с подкреплением (RL). Каждый пример демонстрирует причина поиск проверить отправить конвейер обработки данных.
J.1 Пример 1: Фармакология (MedQA, Correct)
Вопрос: Врач решает, назначить ли лозартан или лизиноприл для лечения гипертензии у 56-летнего мужчины. По сравнению с лозартаном, можно ожидать, что лечение лизиноприлом приведет к каким из следующих изменений в циркулирующих уровнях этих пептидов?? (A) Увеличение брадикинина; снижение ангиотензина II, B) Снижение ренина; увеличение ангиотензина 1, C) Увеличение альдостерона; снижение брадикинина, D) Снижение ренина; увеличение ангиотензина II. Золото: A
-
1.
Ход 1 (Рассуждение): Агент определяет, что лозартан является БРА (блокирует рецепторы AT1), а лизиноприл — ингибитором АПФ (блокирует ангиотензин I). превращение ангиотензина II и деградация брадикинина). Согласно логике, по сравнению с лозартаном лизиноприл увеличивает уровень брадикинина и снижает уровень ангиотензина II..
-
2.
Ход 2 (извлечение доказательств): Поиск запросов «ACE inhibitor vs ARB bradykinin angiotensin II mechanism» для проверки его рассуждений.
-
3.
Ход 3 (поиск_медицинской_вики): Запросы «лизиноприл механизм брадикинин» для дополнительного подтверждения.
-
4.
Ход 4 (проанализировать варианты ответов): Систематически оценивает все четыре варианта в контексте фармакологии RAAS..
-
5.
Ход 5 (отправить_ответ): Отправляет А с рассуждением: «Ингибиторы АПФ предотвращают деградацию брадикинина (увеличивают его уровень) и блокируют Ang I»Конверсия Ang II (снижение).” Оценка: 1.18
J.2 Пример 2: Экстренная медицина (MedQA, Correct)
Вопрос: 56-летний мужчина доставлен в отделение неотложной помощи через 30 минут после падения с высоты 3 фута на острый металлический столб забора. Он находится без сознания. При осмотре выявлена рана глубиной 3 см на верхнем крае правой ключицы по парастернальной линии. Какой из следующих вариантов является наиболее вероятным исходом?? (А) Разрыв вращательной манжеты плеча, (B) Пневмоторакс вследствие повреждения плевры, (C) Парез трапециевидной мышцы вследствие повреждения добавочного нерва, (D) Травматическая аневризма вследствие повреждения внутренней сонной артерии. Золото: B
-
1.
Ход 1 (Рассуждение): Агент сопоставляет локализацию ранения (парастернальная ключичная область) с анатомическими структурами: верхушка легкого в этой зоне выступает выше ключицы, что делает повреждение плевры основной проблемой. Исключаются повреждения вращательной манжеты (слишком латерально), добавочного нерва (слишком дорсально) и внутренней сонной артерии (слишком латерально/глубоко).).
-
2.
Шаги 2–3 (search_pubmed, извлечение доказательств): Поиск по запросу «проникающее повреждение ключицы парастернальное повреждение плевры» и извлечение медицинской литературы об осложнениях при проникающей травме надключичной области..
-
3.
Ход 4 (думать): Синтезирует полученные данные с анатомическими знаниями, подтверждая, что купол плевры простирается на 2,5 см выше медиальной трети ключицы..
-
4.
Ход 5 (submit_answer): Отправляет Сфера статьи: Искусственный интеллект, когнитивные науки, нейронные сети, нейролингвистическое программирование (NLP), продуктивность, ИИ-агенты. (пневмоторакс вследствие повреждения плевры). Балл: 1.18
J.3 Пример 3: Трансплантационная медицина (MedQA, Correct)
Вопрос: У 37-летнего мужчины, перенесшего трансплантацию печени 7 лет назад и получающего иммуносупрессивную терапию, отмечаются рецидивирующая желтуха (6–7 эпизодов), значительное повышение печеночных ферментов и снижение печеночного кровотока по данным допплерографии. Какие гистологические изменения следует ожидать?? (A) Пролиферация желчных протоков с нейтрофильной инфильтрацией, (B) Баллонная дистрофия гепатоцитов с жировой дистрофией, (C) Гранулематозное воспаление с многоядерными гигантскими клетками, (D) Интерстициальная клеточная инфильтрация с паренхиматозным фиброзом, облитерирующий артериит. Золото: D
-
1.
Ход 1 (думать): Агент идентифицирует это как хроническое отторжение трансплантата на основании: срок после трансплантации — 7 лет (позднее начало), рецидивирующая желтуха несмотря на соблюдение терапии, снижение сосудистого кровотока по данным допплерографии (что указывает на сосудистую патологию) и резко повышенные ферменты, свидетельствующие о продолжающемся повреждении трансплантата..
-
2.
Поворот 2 (анализировать варианты ответов): Систематически сравнивает варианты: пролиферация желчных протоков (острое отторжение), баллонная дистрофия гепатоцитов (жировая болезнь печени), гранулематозное воспаление (саркоидоз/туберкулез), облитерирующий артериит с фиброзом (характерный признак хронического отторжения).).
-
3.
Ход 3 (поиск_медицинской_вики): Поиск «хроническое отторжение трансплантата печени облитерирующий артериит гистология» для подтверждения.
-
4.
Ход 4 (Рассуждение): Интегрирует клинические и гистологические данные: облитерирующий артериит является патогномоничным признаком хронического отторжения, что объясняет снижение кровотока по данным допплерографии..
-
5.
Ход 5 (отправить_ответ): Отправляет D с подробным обоснованием связи клинической картины с гистопатологией. Оценка: 0.80
Ключевые наблюдения.
Эти траектории выявляют три устойчивых паттерна у агентов, обученных по методу TT-OPD: (1) Причинно-ориентированный: агент формулирует гипотезу перед поиском, сокращая количество нерелевантных вызовов инструментов; (2) Грациозная деградация: когда специализированные инструменты поиска не срабатывают (например, серверная часть PubMed недоступна), агент переключается на альтернативные инструменты или внутренние знания вместо остановки; (3) Петля верификации: агент использует думать и проанализировать варианты ответов перекрестно проверять полученные доказательства в сравнении с исходными рассуждениями перед фиксацией submit_answer.